内存使用与分段
如何让内存用起来
仍然从计算机如何工作开始…
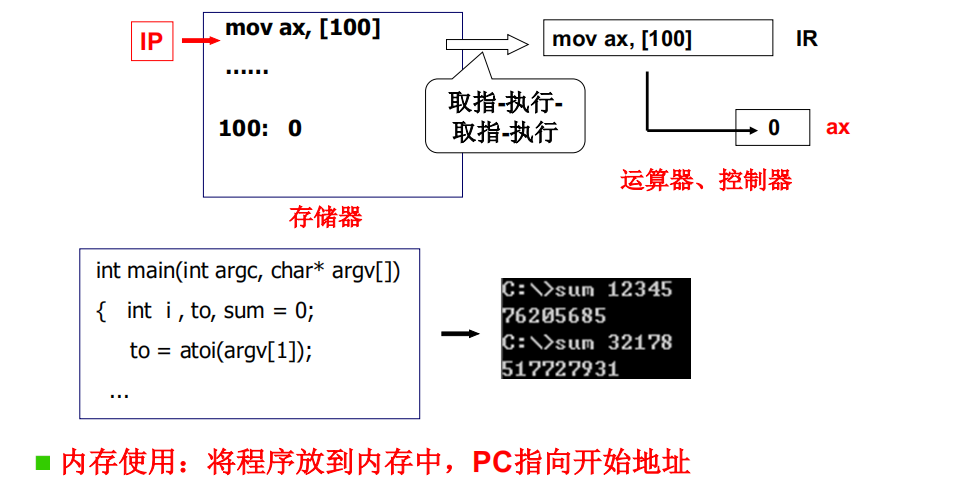
那就让首先程序进入内存
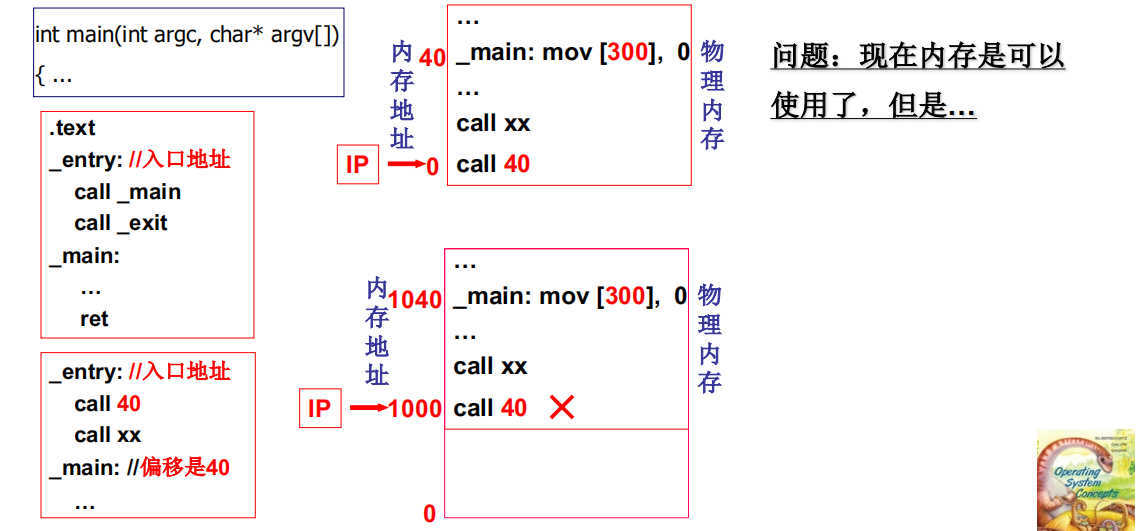
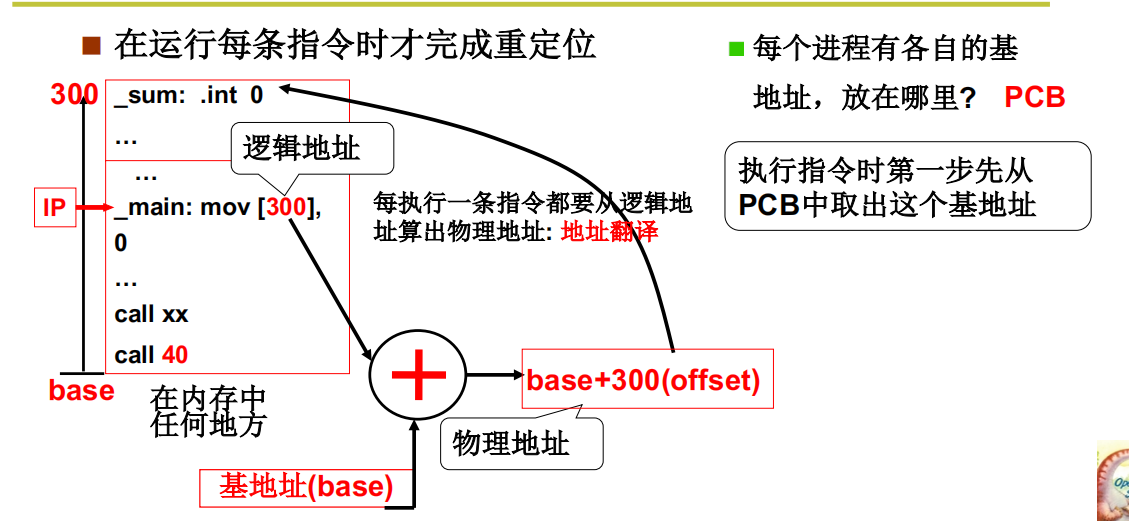
重定位:修改程序中的地址(是相对地址)

程序载入后还需要移动
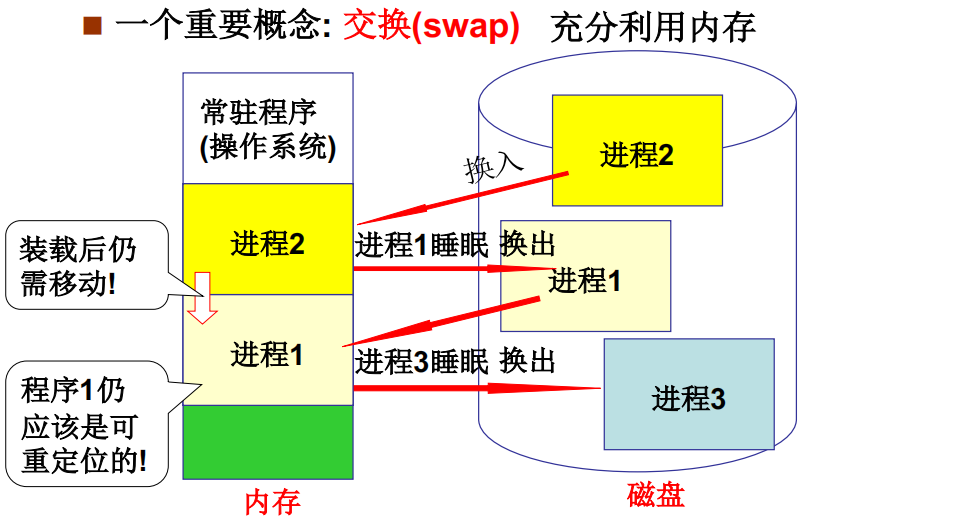
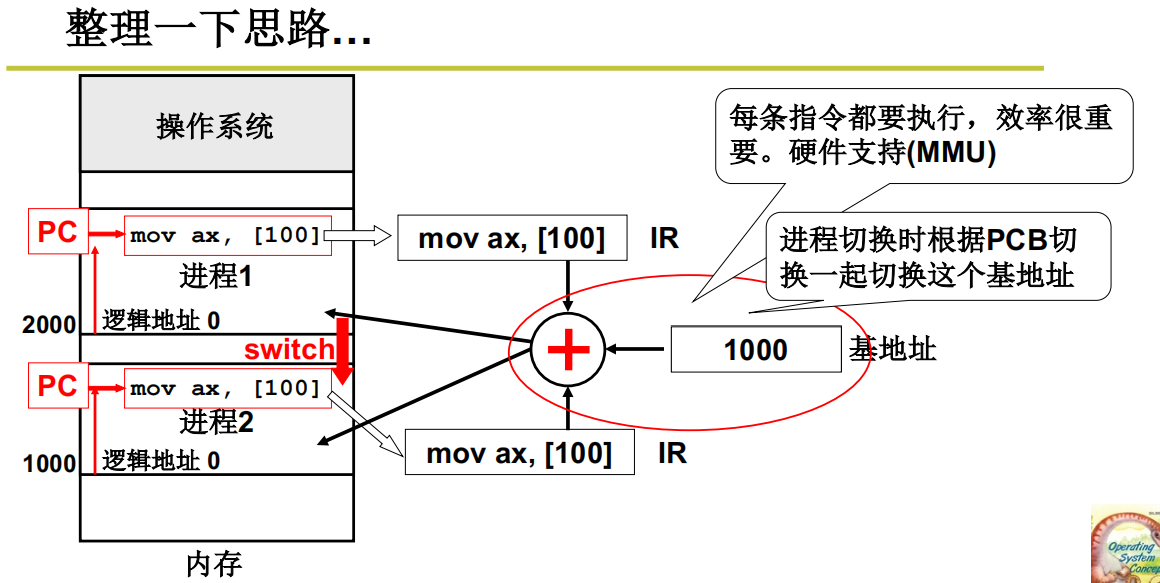
重定位最合适的时机 - 运行时重定位
引入分段:是将整个程序一起载入内存吗
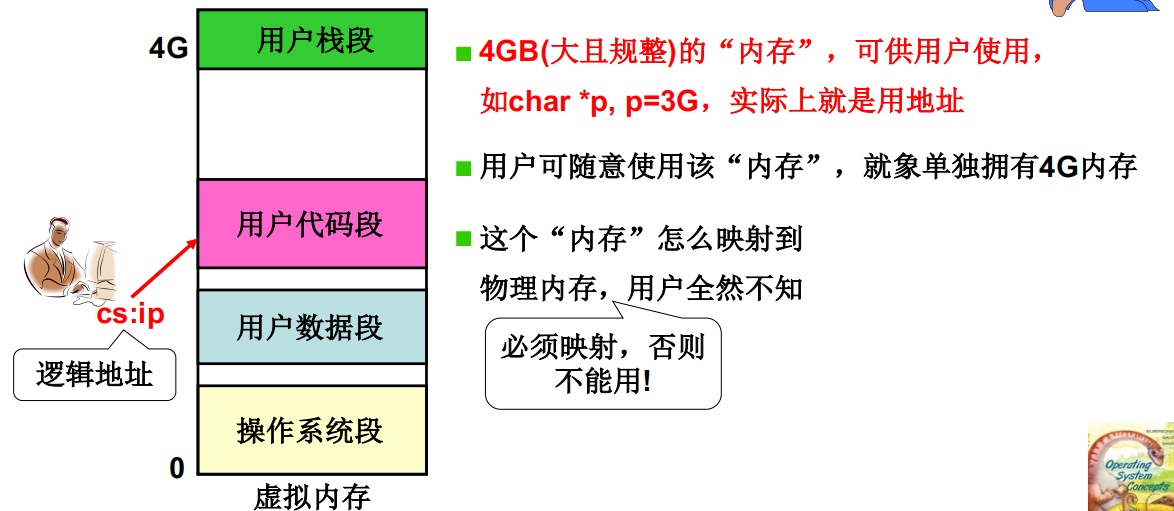
程序员眼中的程序
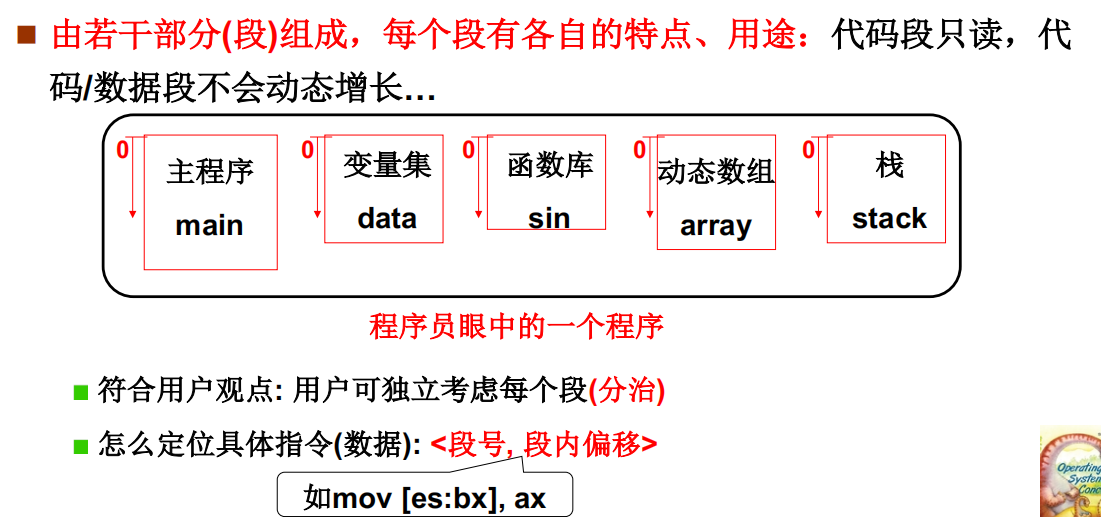
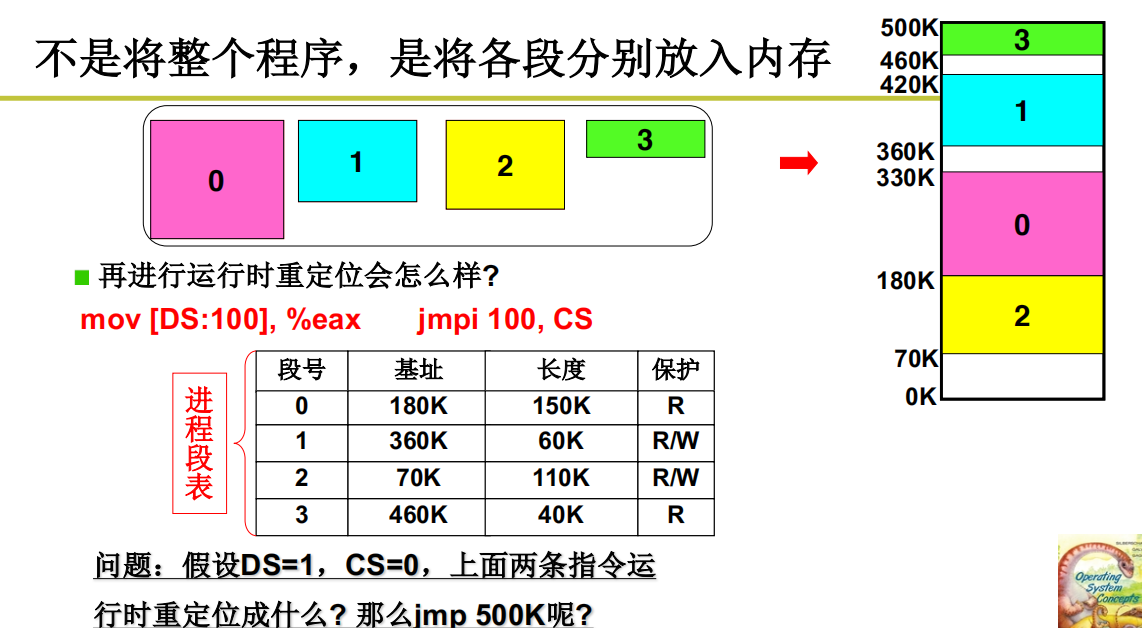
不将整个程序,是将各段分别放入内存
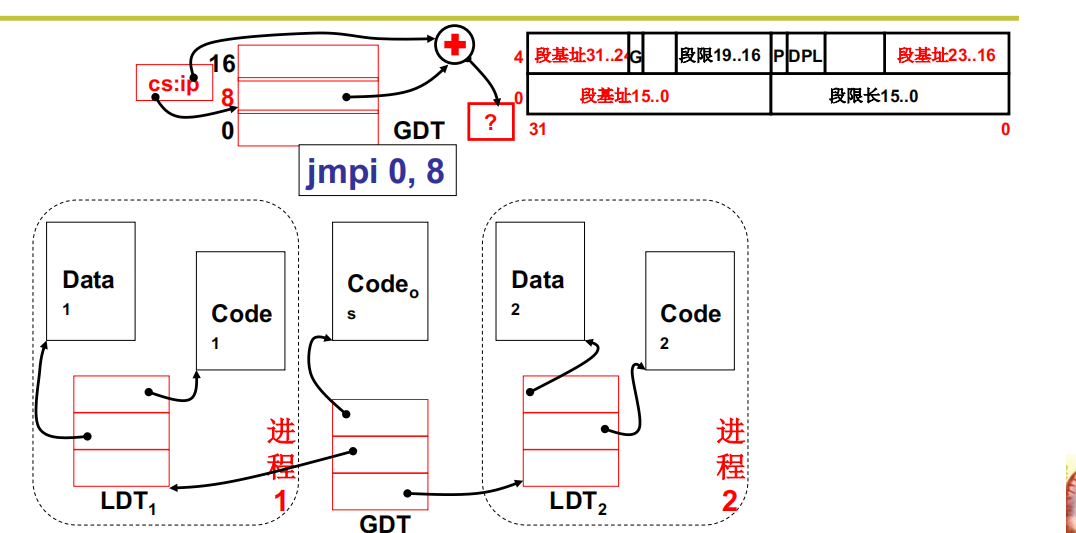
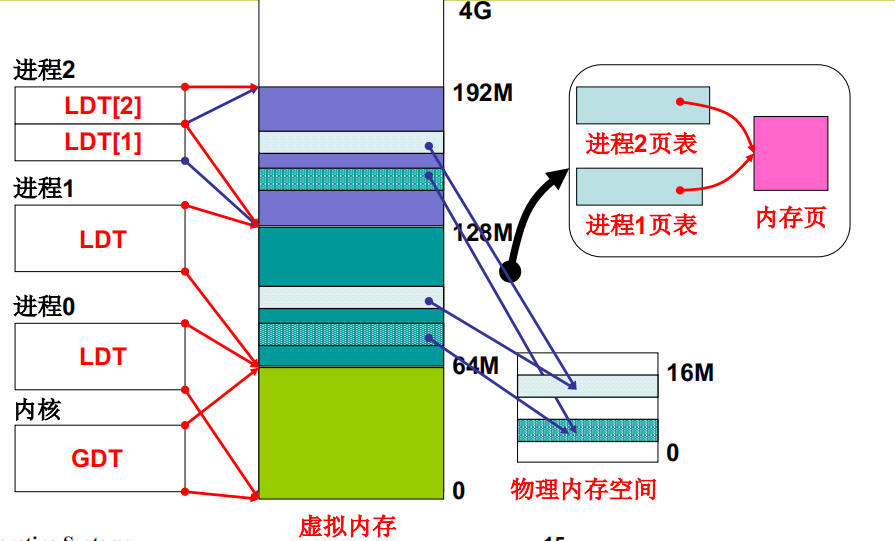
GDT表是OS对应的段表,每个进程的段表叫做LDT
真正故事:GDT, LDT
内存分区和分页
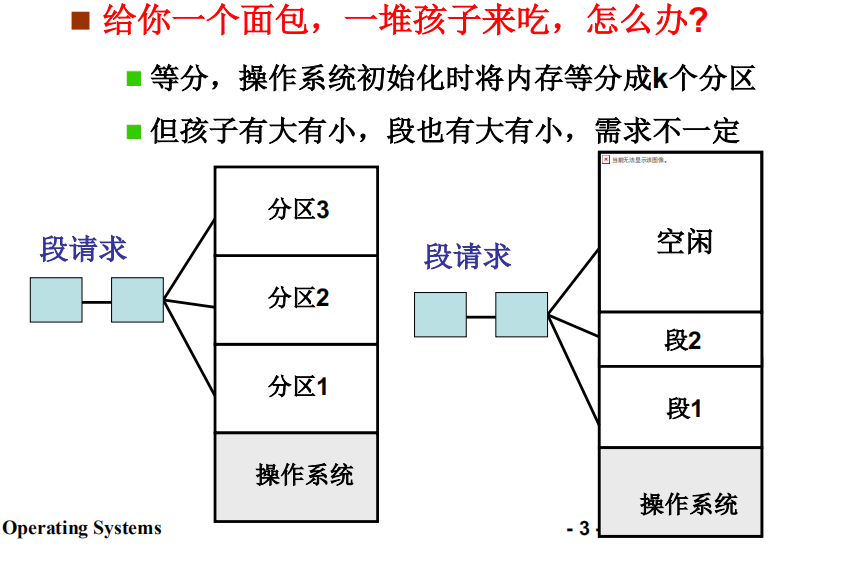
接下来的问题是内存怎么割
这样就可以将程序的各个段载入到相应的内存分区中了
固定分区与可变分区
可变分区的管理过程 - 核心数据结构
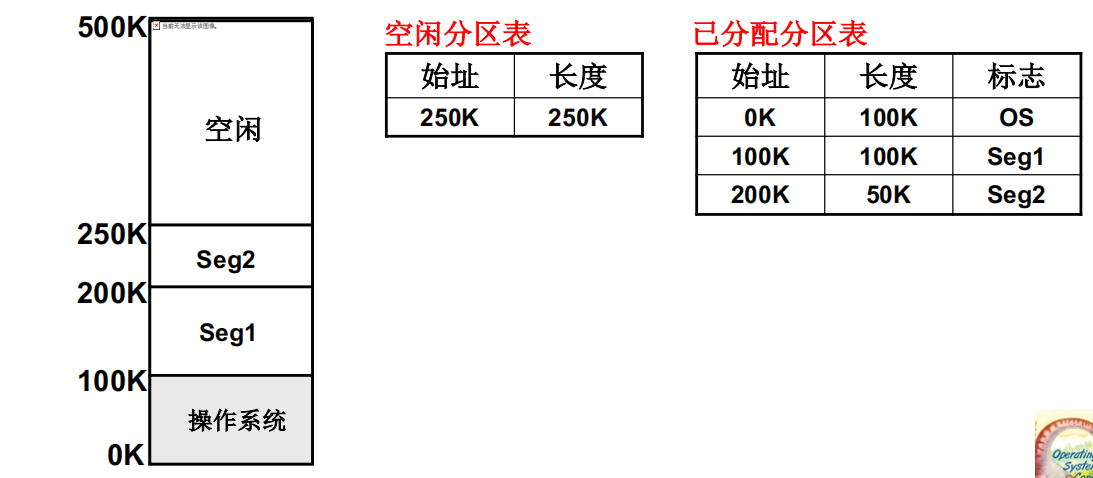
可变分区的管理-请求分配
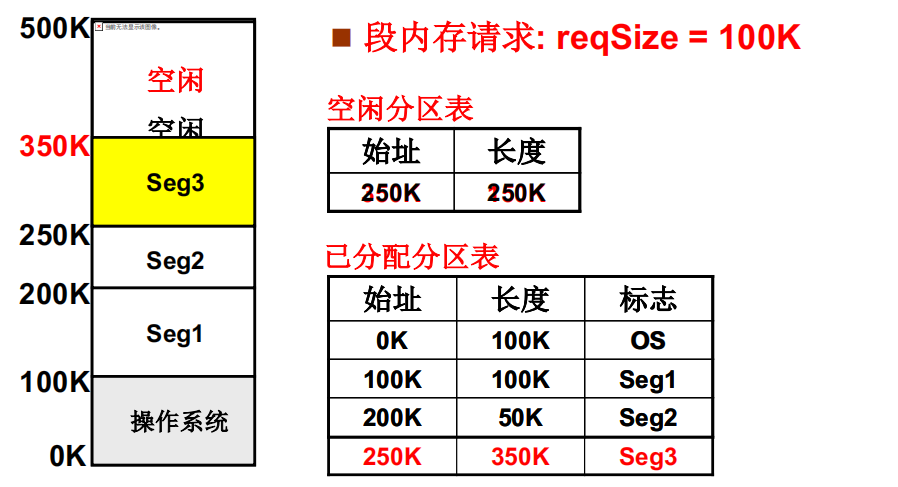
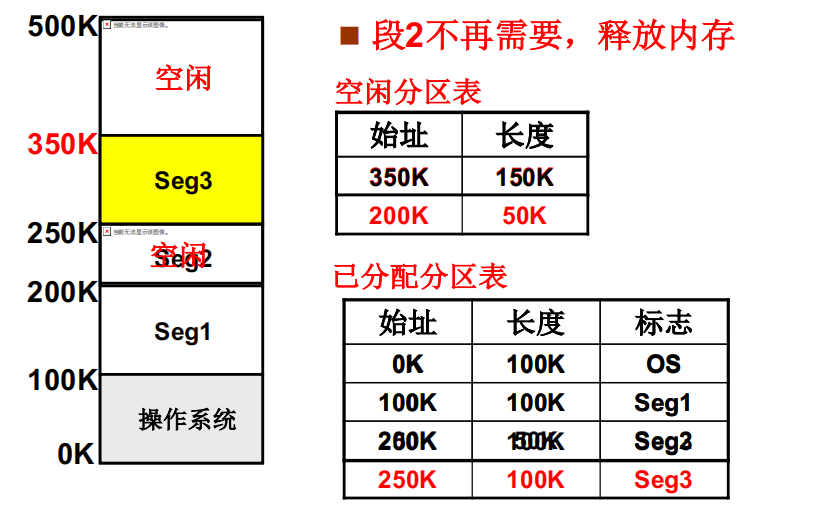
可变分区的管理-释放内存
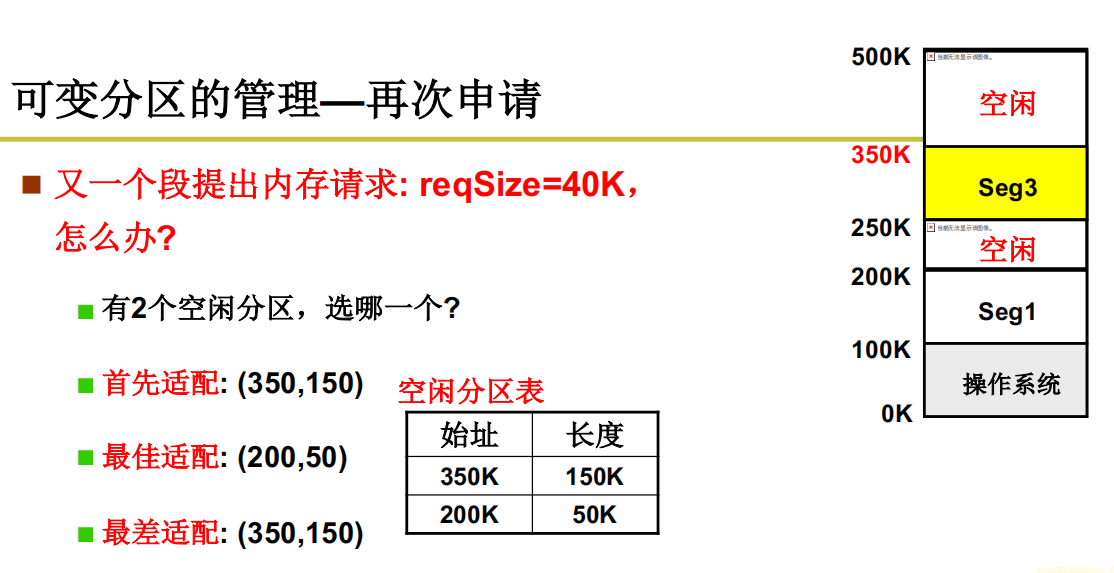
可变分区的管理-再次申请
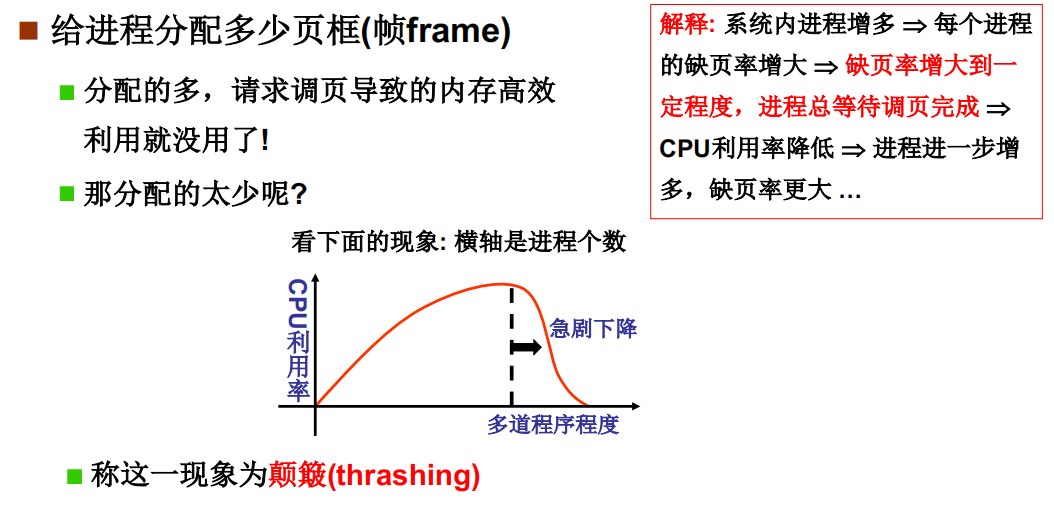
引入分页:解决内存分区导致的内存效率问题
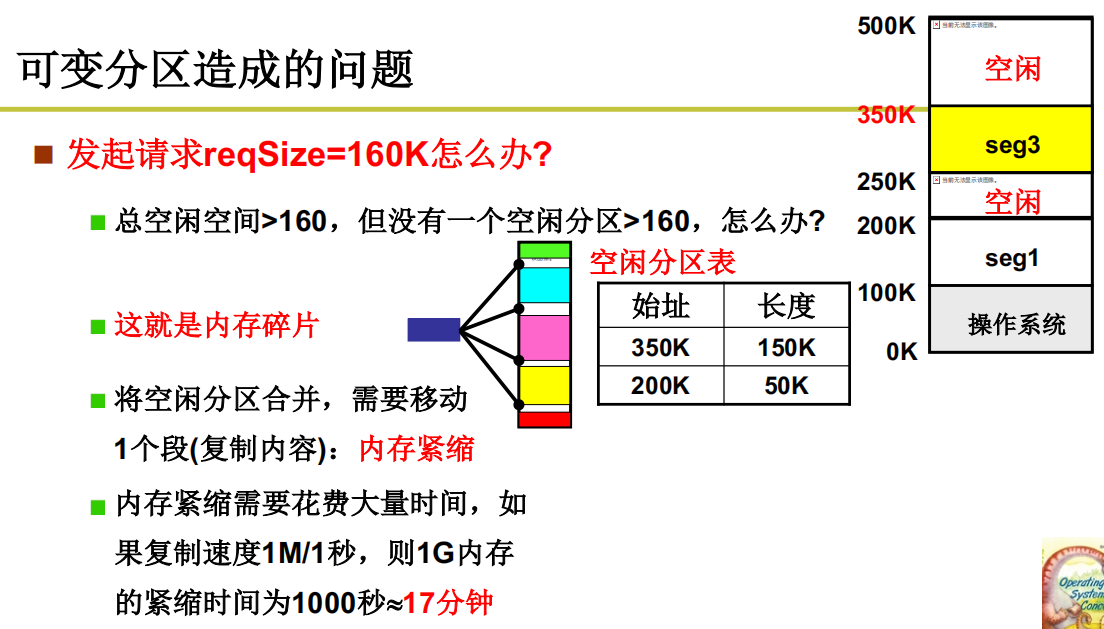
可变分区造成的问题
从连续到离散

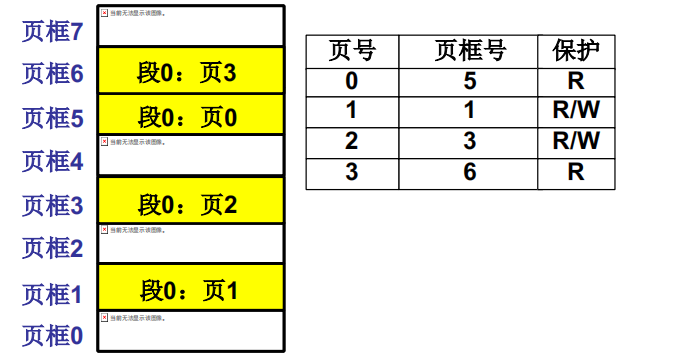
页已经载入内存,接下来的事情
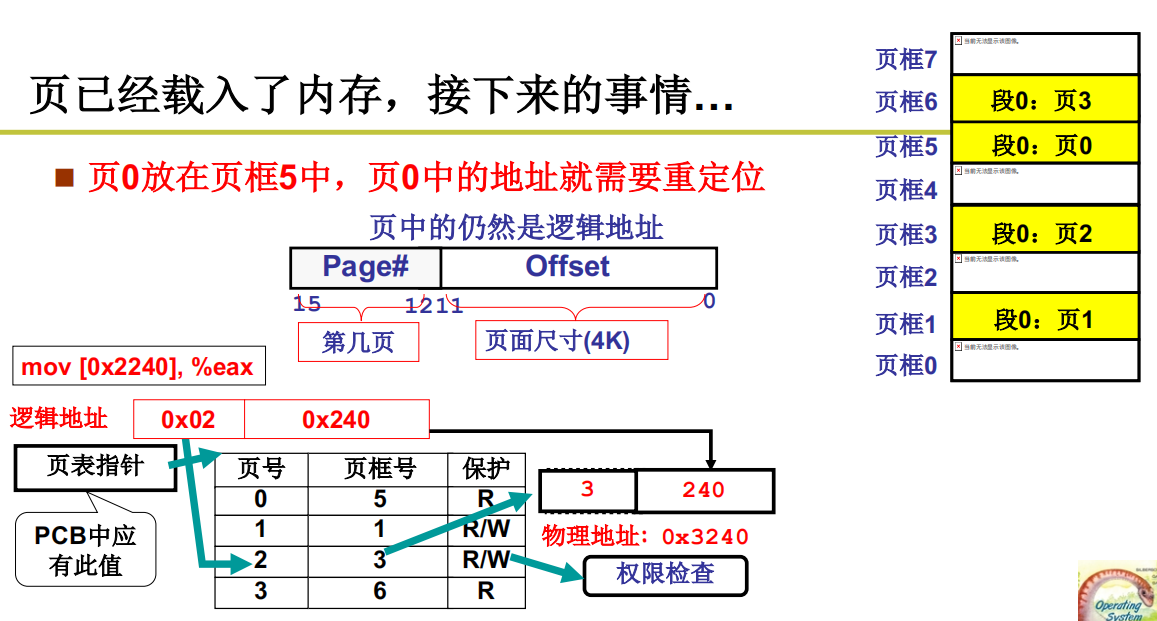
页表寄存器存放当前进程的页表地址Cr3
多级页表和快表
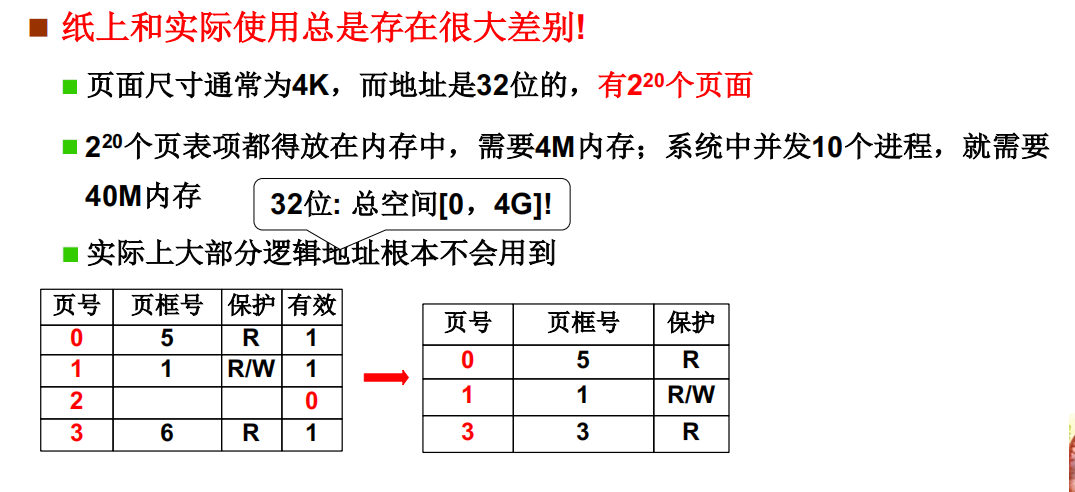
为了提高内存空间的利用率,页应该小,但是页表小页表就大了
页表会很大,页表放置就成了问题
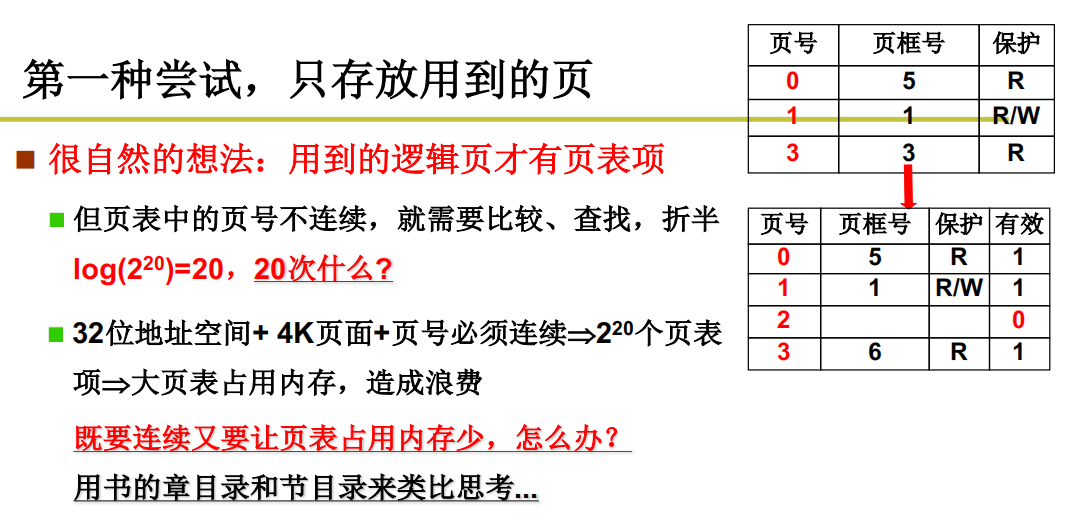
第一种尝试,只存放用到的页
第二种尝试:多级页表,即页目录表(章)+页表(节)
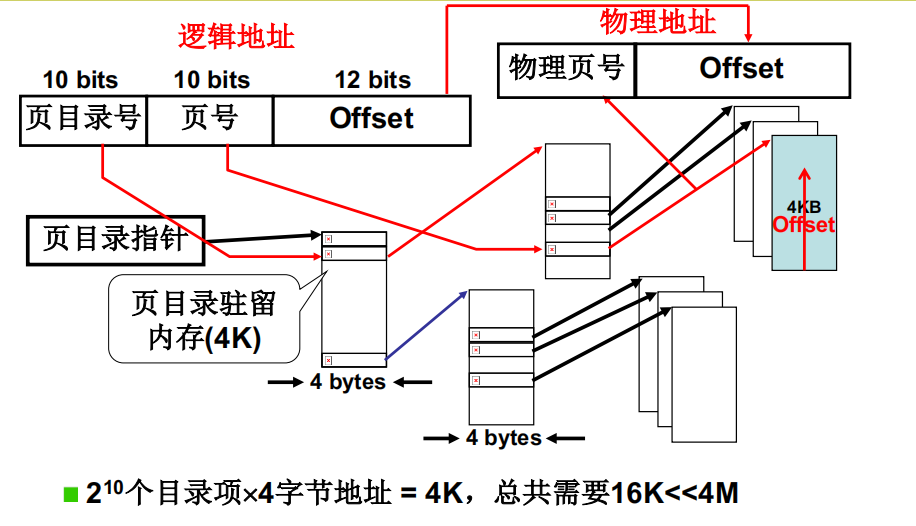
一些不用的页目录表无需进行映射
多级页表提高了空间效率,但在时间上?
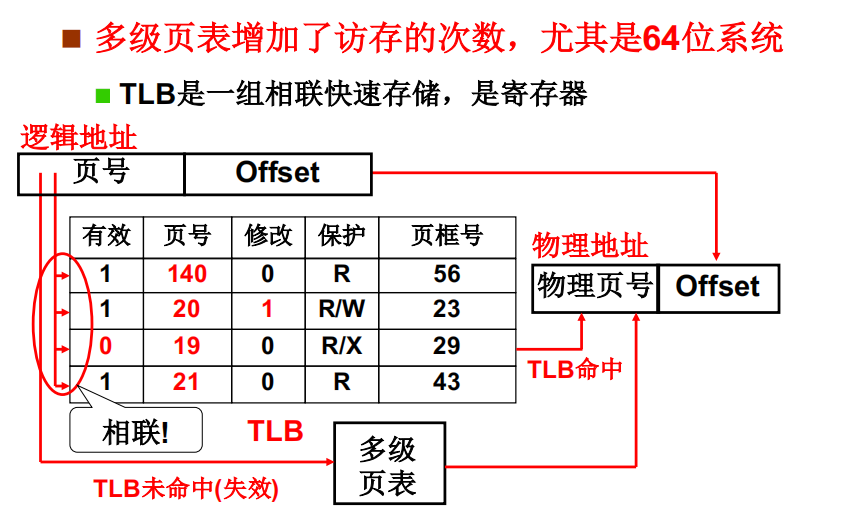
每增加一级页表,就需要多访问一次内存
通过引入TLB来解决
TLB得以发挥作用的原因

段页结合的实际内存
段、页结合: 程序员希望用段,物理内存希望用页,所以…
段页同时存在:段面向用户/页面向硬件
段页同时存在时的重定位(地址翻译)
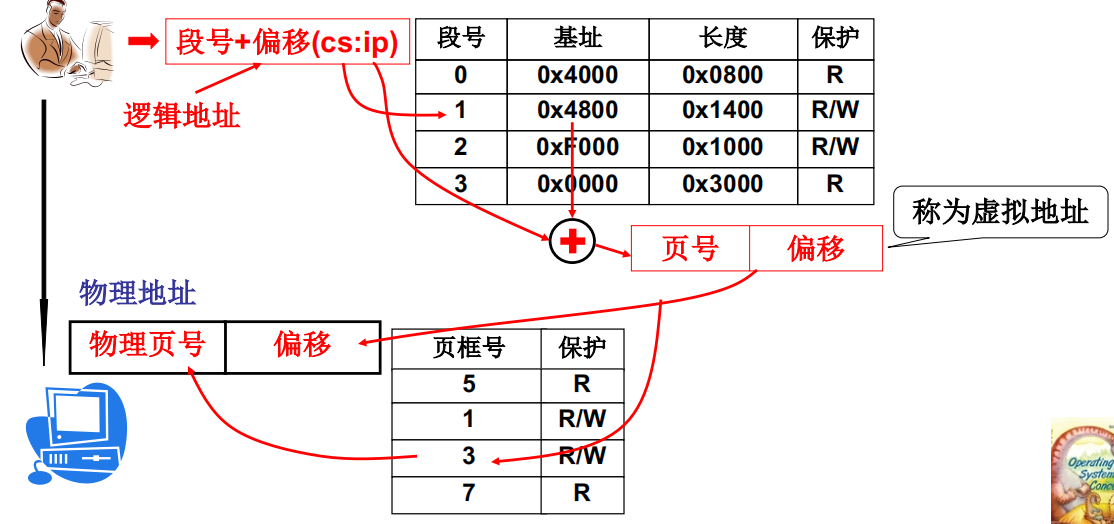
段、页结合时进程对内存的使用
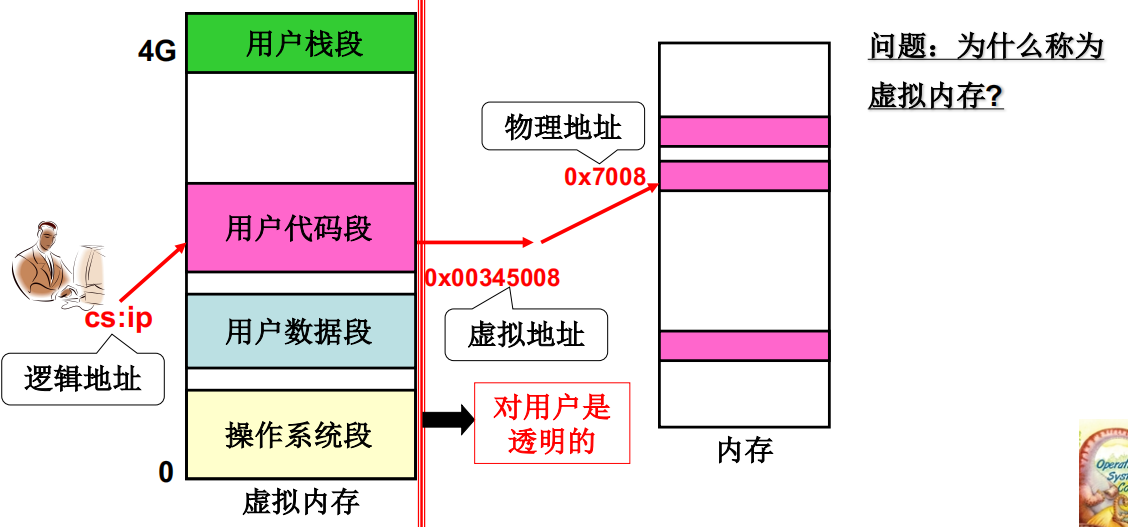
程序如何放入内存中?
在虚拟内存中分割出一些分区,将程序的各个段 “放入” , 分区算法可以使用前面讨论过的适配算法。由于虚拟内存并没有对应真实虚拟存储单元,所以这里并不是真的放入,而是建立映射关系,假装放入
建立段表来记录这个映射关系
将虚拟内存分割成页,选择物理内存中的空闲页框,将虚拟内存中的“页内容”放到物理物理页框中。由于虚拟内存是不存放实际内容的假内容,所以这里的页内容实际上是曾经假装放入虚拟内存的程序段内容。
因此,基于虚拟内存的段页结合效果是将程序段分割成页以后载入物理页框中,但这个载入是通过虚拟内存才完成的。一旦经过虚拟内存,从用户出发看到的视图是程序段被放到一个连续的“区域”上,即用户看到的分段效果。在背后,操作系统再将这个“内存区域”按照分页方式真正放到物理内存里,实现了分页机制
建立页表来记录虚拟内存和物理内存页框之间的映射关系。
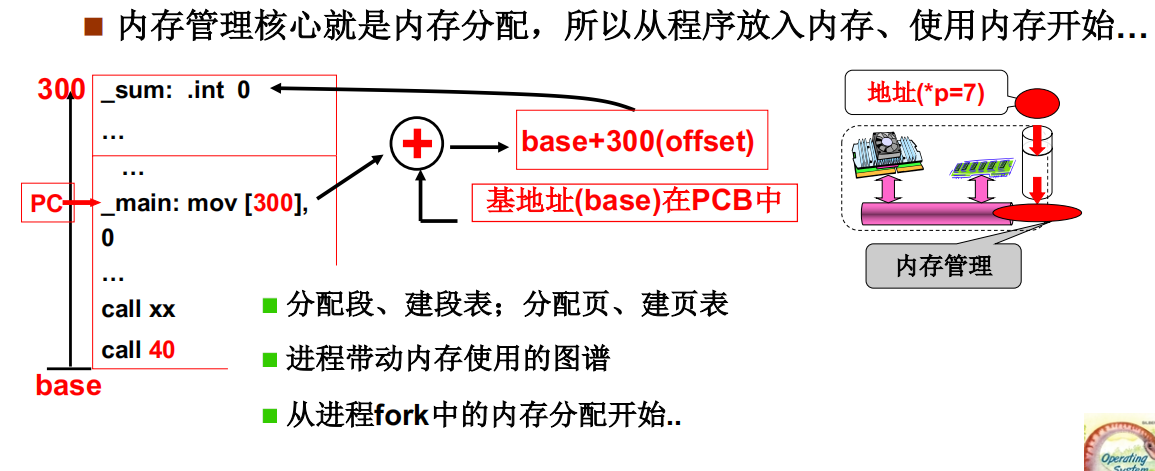
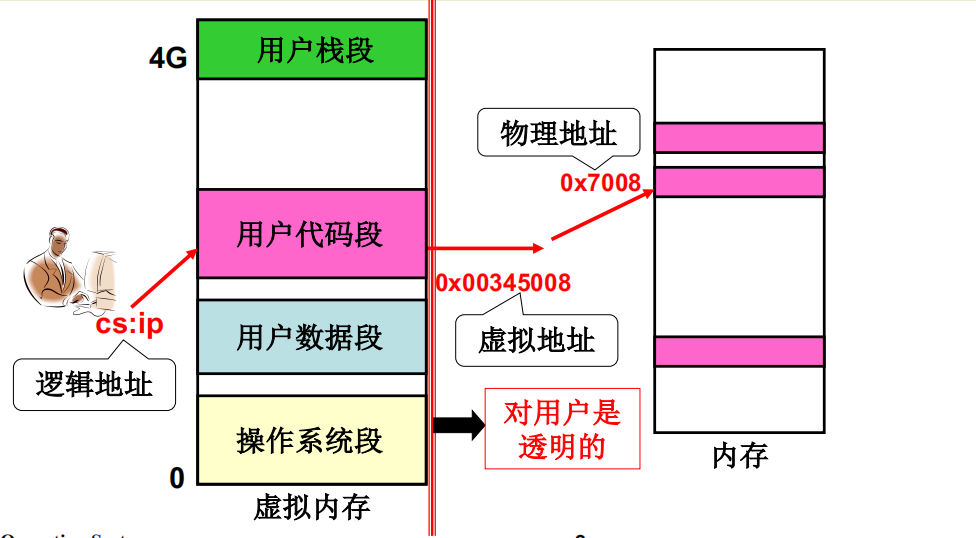
放到内存中的指令如何正确执行呢?
以call 40为例,执行该指令时要进行地址转换:逻辑地址是 CS:40,假定代码段是第0段。先找段表取出基址, 可以算出这个CS: 40在虚拟内存中的位置,1000 + 40 = 1040, 这个地址被称为虚拟地址。因为虚拟内存分割成页映射到物理页框,现在要根据虚拟地址查页表找到物理地址,1040对应的虚拟页号是 1040 / 100 = 10…40 , 虚拟页号是10, 页号偏移是40。查找页表得到物理页框号5,最终的物理地址是540。在地址总线上放入地址540后进行取指,取出的指令正好是mov 1, [300],指令call 40被正确的执行了。
只要将特定寄存器(LDTR 和 CR3)的值设置为段表起始地址和页表起始地址,执行每条指令时 MMU 都会自动地、正确地完成上述地址转换过程。因此只要能正确地将磁盘上的内容按特定结构载入内存,并设置好段表和页表,进程中的指令就能正确地执行。而随着进程的不断执行,内存也会跟着工作。
一个实际的段、页式内存管理
故事从哪里开始呢
段、页式内存下程序如何载入内存
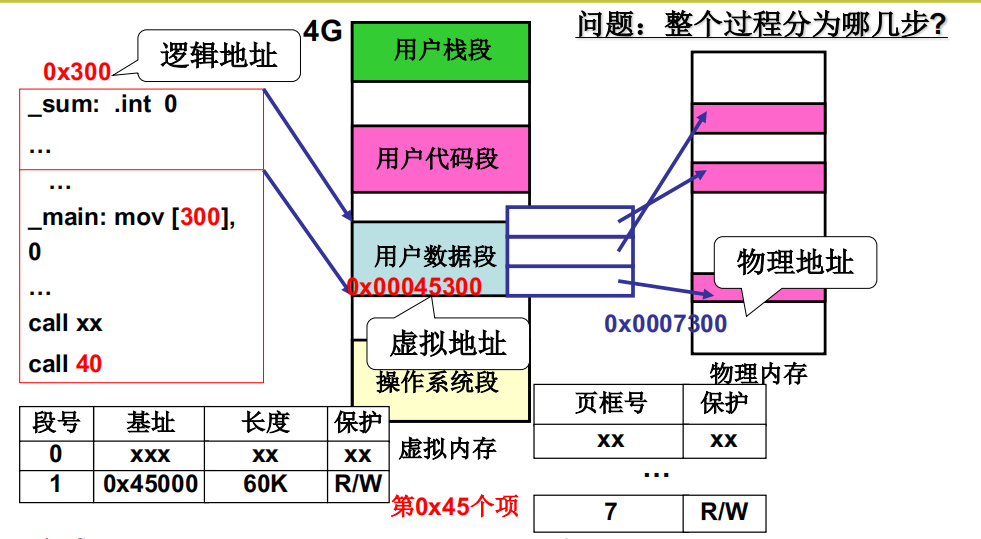
首先要在虚拟内存中割出一段区域给用户的代码段、数据段,怎么割出来呢?可以使用分区算法,对虚拟内存进行分区,分区只是存放空闲区域的起始地址和长度,分出来的区之后在通过地址映射和物理内存的页框关联起来,完成分页映射
故事从 fork()开始
进程创建中关于内存的使用就是将程序载入内存中,所以此处的代码实现要完成的核心工作就四件事:
- 在虚拟内存中分段
- 建立段表
- 将虚存页映射到物理页框
- 建立页表
进程管理通过copy_process函数完成 PCB的创建,完成内核栈的分配与初始化、完成内核栈和PCB之间的关联等,现在,内存管理要在这个函数中给进程建立地址空间

这里的copy_mem(nr, p)就是要为进程建立内存空间,之所以称为copy,因为要复制父进程的内存空间
这一段 的核心动作就是set_base(p->ldt[1]),这条语句就是向进程的LDT中写内容,因此就是建立段表。
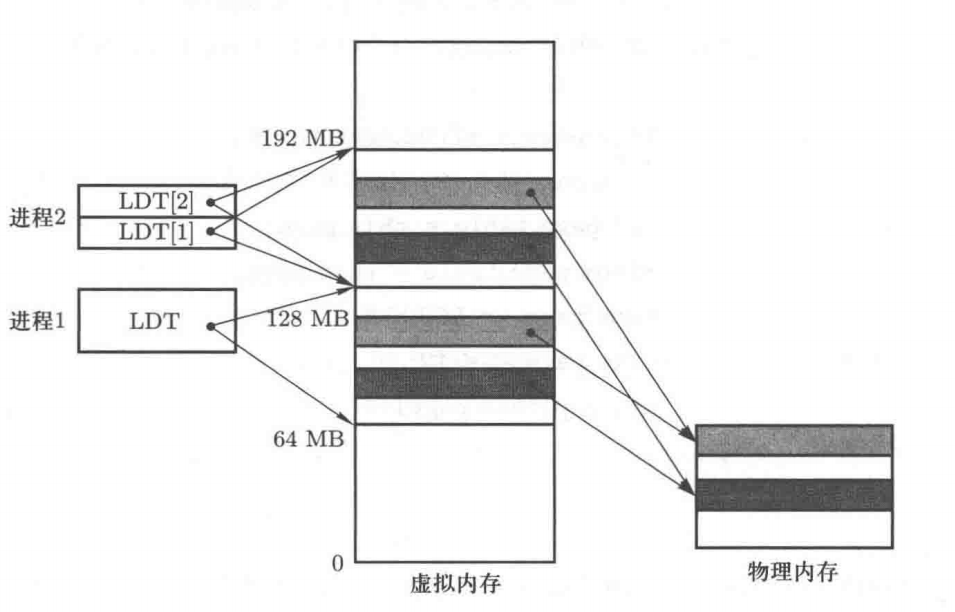
设置new_data_base是虚拟内存的基址, 0号进程的 nr = 0, 1号进程的 nr = 1,以此类推,每个进程都分割了 64M的虚存空间,且任意两个进程的虚存地址空间没有重叠
因此重要功能就是分配虚存,建段表
这样的等分方式显然是一种最简单的虚存分割方法,我们完全可以使用更复杂的虚存管理方法,比如最佳适配算法,基于AVL平衡树的分区管理算法等。实际上这种简单的等分方法时间效率最高,完全可以应用在诸如嵌入式计算等不要求灵活而更注重执行速度的操作系统中。
进程0、进程1、进程2的虚拟地址
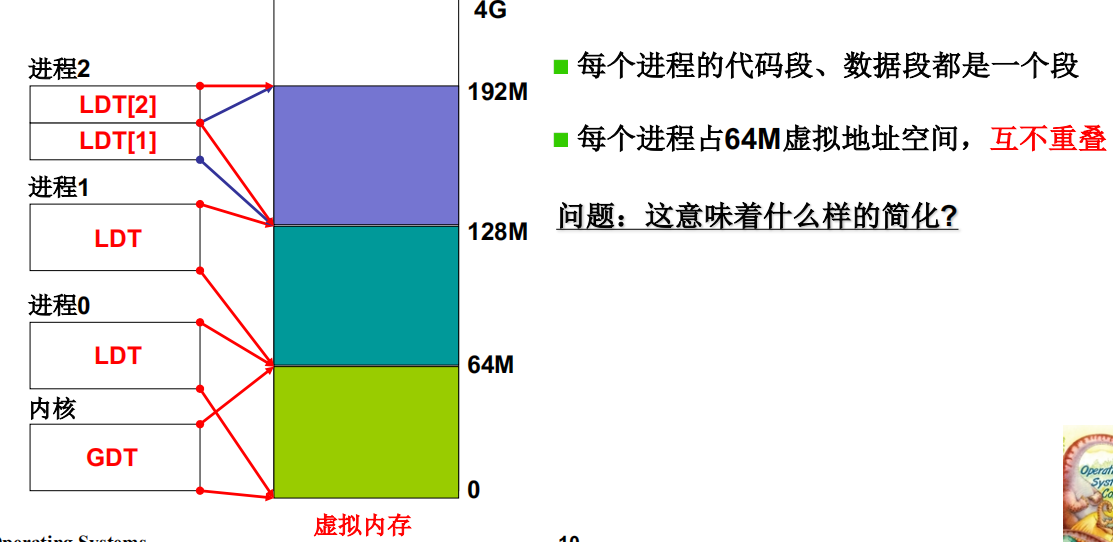
在Linux0.11中
- 每个进程的代码段、数据段都是一个段
- 每个进程占64M虚拟地址空间,互不重叠
接下来 分配内存、建页表
段处理好之后,接下里要做的就是实现分页,建立页表。实际上,物理内存分页在系统初始化时已经做好了,在系统初始化函数mem_init中已经填好mem_map数组。数组mem_map中的每一项表示一块 4KB 内存是否空闲,当时将数组 mem_map中的元素都初始化为 0 (空闲),显然,这里的mem_map就是用来管理物理内存页的数据结构。
将物理内存分割成页框的工作在OS初始化时已经做好,接下来要做的工作就是将进程使用的虚拟内存分割成页,并且和物理页框建立映射关系,这显然是 copy_mem接下来要做的工作。
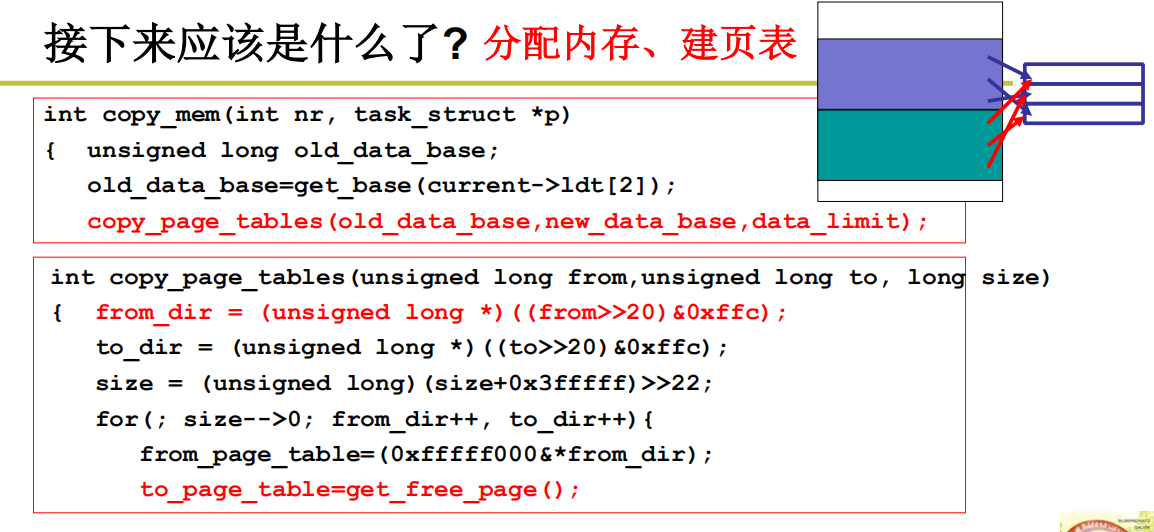
根据函数的名字copy_page_tables(old_data_base, new_data_base, data_limit)不难想到,其功能是将父进程的虚存空间(语句 old_data_base = get_base(current->ldt[2]))用来得到的父进程的虚存空间和内存物理页框的映射关系复制给子进程的虚存空间 new_data_base.
不难想象复制后的结果如图,正是因为这个复制动作,建立子进程内存空间的函数称为 copy_mem,也正是因为这个复制动作,if(!fork()) { ... }以后,父子进程执行同样的代码
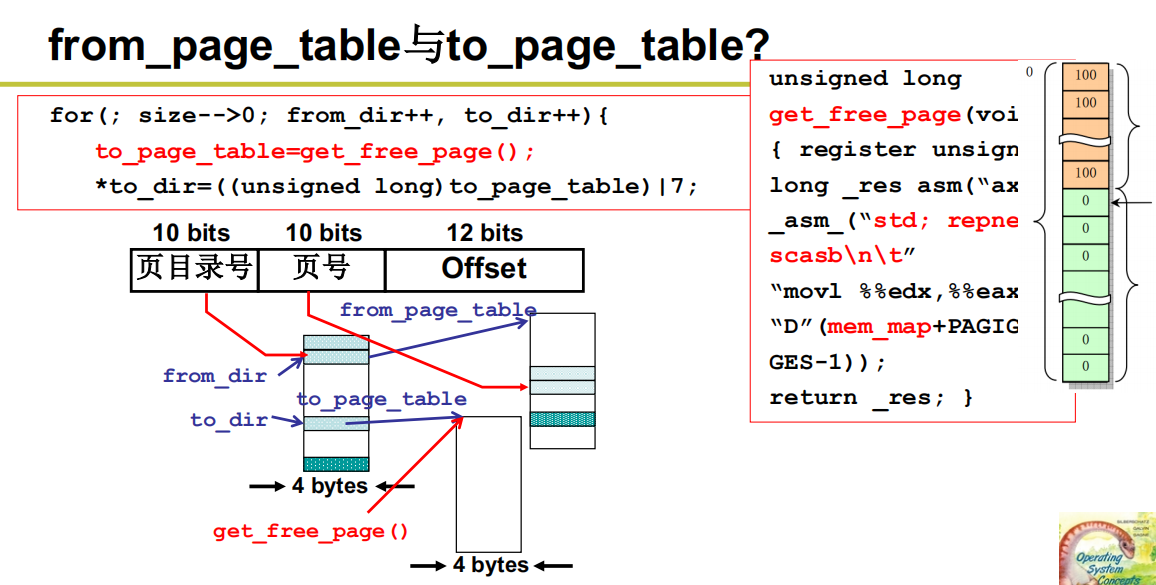
用代码实现copy_page_tables:根据页目录项和页表项构成的两级目录结构,首先找到页目录项。虚拟地址 from 向右移动 22 位得到的就是页目录号,由于页目录表中每个页目录项的长度都是 4个字节,所以页目录号再乘 4 就是页目录项再页目录表中的位置,对应的代码就是(from >> 22) * 4, 也就是((from >> 20)& 0xffc).
页目录项在页目录表中的位置再加上页目录表的起始地址就是页目录项所在的内存地址,由于页目录表被初始化在内存的 0 地址处(系统初始化 head.s 中有对初始化页目录表的代码),所以从地址((from >> 20) & 0xffc)处取出来的内容就是父进程虚拟内存对应的页目录项中存放的内容,即页表地址。有了页表地址就可以逐个复制页表项了,复制完成后构建完成上图结构。
1 | int copy_page_tables(unsigned long from, unsigned long to, long size) { |
可以用循环 for(; from_dir++, to_dir ++) 将父进程一个页目录项下的所有页表项(一个页目录对应1024个页)复制到子进程对应的那个页目录项下面。由于每个进程的64MB虚拟内存包含多个页目录项,实际上不难算出,每个页目录项可以表示 1024 * 4 KB, 即4MB大小的地址区域,64MB虚拟内存包含16个页目录项,所以才有这个 for 循环。
循环体内部的 from_page_table = (0xffff00 &*from_dir) 得到父进程目录项指向的 1024个页表项的起始地址
语句 to_page_table = get_free_page() 用来分配一个新的内存页来存放子进程对应的 1024 个页表项
语句 to_dir = ((unsigned long) to_page_table | 7) 完成子进程页目录项和页表的关联。
get_free_page() 的实现很容易想到:就是在 mem_map数组中找到一个内容为 0 的项,并返回该项对应的物理地址。
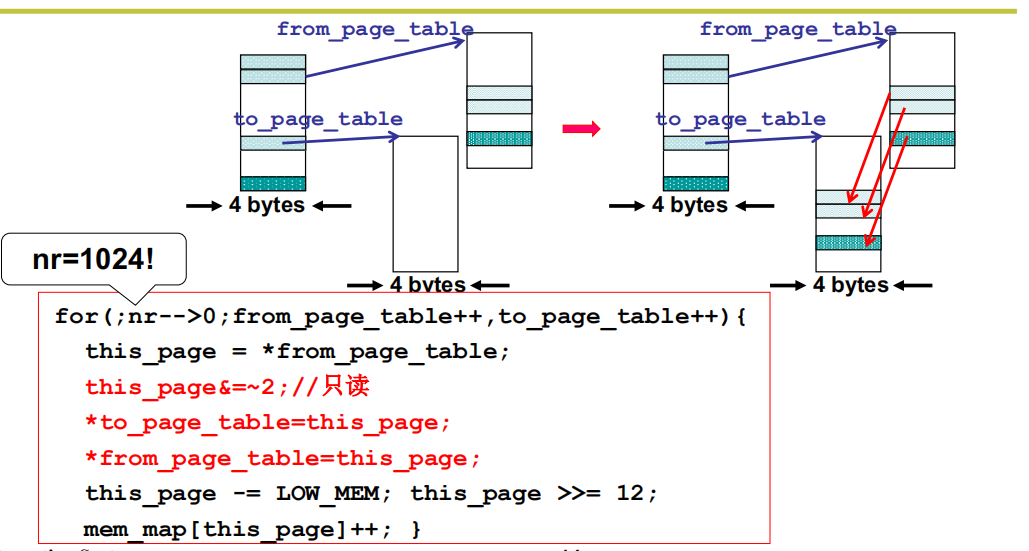
循环 for(; nr–>0; from_page_table++, to_page_table ++) 用来完成页表项内容的复制,一旦完成页表项内容的复制,上面图中的结构就形成了。循环中的 this_page = *from_page_table 用来得到父进程虚拟页对应的物理页框号,将这个页框号填写到子进程的页表项中就完成了复制,所以有语句 *to_page_table = this->page。
由于现在父子进程使用了同样的物理页框,所以这个物理页框要变成只读,因为如果父子进程都可以写,那么两个进程并发执行时就会互相影响而导致错误,语句 this_page &= 2 将页表倒数第二位设置为 0,用来表示这个页只读。当然,现在两个进程使用同一个物理页框,物理页框的计数器应该增加 即 mem_map[this_page] ++;, 这样可以防止父子进程中的一个进程释放内存时将这个物理页框释放掉。

指向页表项的地址
from_page_table 和 to_page_table
循环每一个页目录,子进程需要拷贝出一摸一样的内容,此时 to_dir没有被占用,也没有映射到物理内存,现在需要映射,需要分配物理内存建页表
接下来干什么应该也猜得到
程序、内存 + 虚拟内存的样子
*p = 7 ? 父进程 *p = 7、子进程 *p = 8
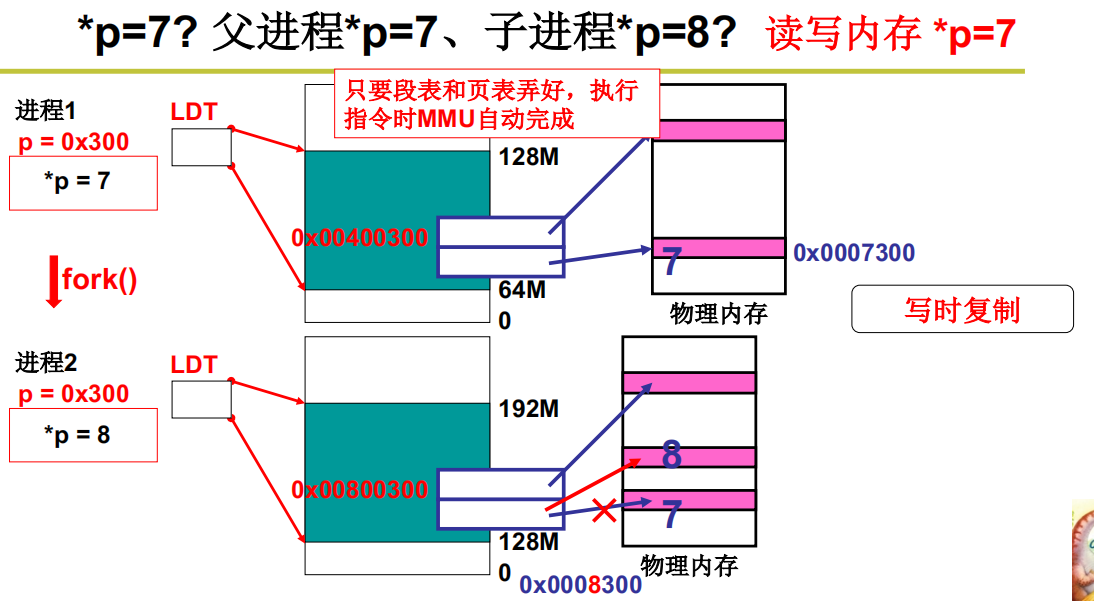
此处父进程执行语句 *p = 7为例来分析内存是如何操作,父进程建立好段和页之后,此时执行语句 *p = 7, 假定编译后 p 的逻辑地址是 0x300。为了计算出物理地址,MMU首先找到数据段地址,即从当前进程的LDT[2]中找到基址,对于这个例子假设是 0x04000000,从而算出虚拟地址是 0x04000300。接下来根据虚拟地址查找页表得到物理地址,根据页表该虚拟页对应的物理页框号是 3,所以物理地址是 0x0007300。MMU会将 0x0007300发送到地址总线上,从数据总线上取回来的内容是 7 ,print(*p)输出还是 7.
现在子进程执行语句 *p = 8, 此时逻辑地址 0x300 经过地址转换以后得到的物理地址仍然是 0x0007300,现在要往 3号物理页框中写内容。别忘了,fork()时将这个页框设置为只读,现在要写,因此会出现内存读写异常中断,中断系统的处理结果是新分配一个页给出子进程,这就是著名的写时复制,操作系统会为虚存空间 0x00800300处的虚拟页新申请一个物理页框(调用get_free_page()获得一个空闲物理页),此处是申请了8号物理页,再修改页表完成 0x00800300处第一个虚拟页和 8号物理页框的映射。
现在需要重新执行指令 *p = 8, 因为刚才执行该条指令时出现了读写异常中断,相当于指令没有执行。再次地址转换以后得到的新的物理地址是0x0008300, MMU会将 0x0008300发送到地址总线上,CPU会将 8 发送到数据总线上,结果是0x0008300处的内容变为 8
此时如果父进程再次执行 printf(*p),又会打印什么呢?再进行地址转换:从父进程的LDT[2]中取出基址 0x00400000,得到虚拟地址0x00400300。根据虚拟页号查找页表,物理页框号是3,得到物理地址0x0007300, MMU会将0x0007300发送到地址总线上进行读操作,从数据总线上取出来的内容是 7,父进程执行 printf(*p) 还是打印7。现在父进程的 *p 处存放的是7,子进程 *p 处存放的是 8,此时父子进程完全分离,实现了地址分离效果。
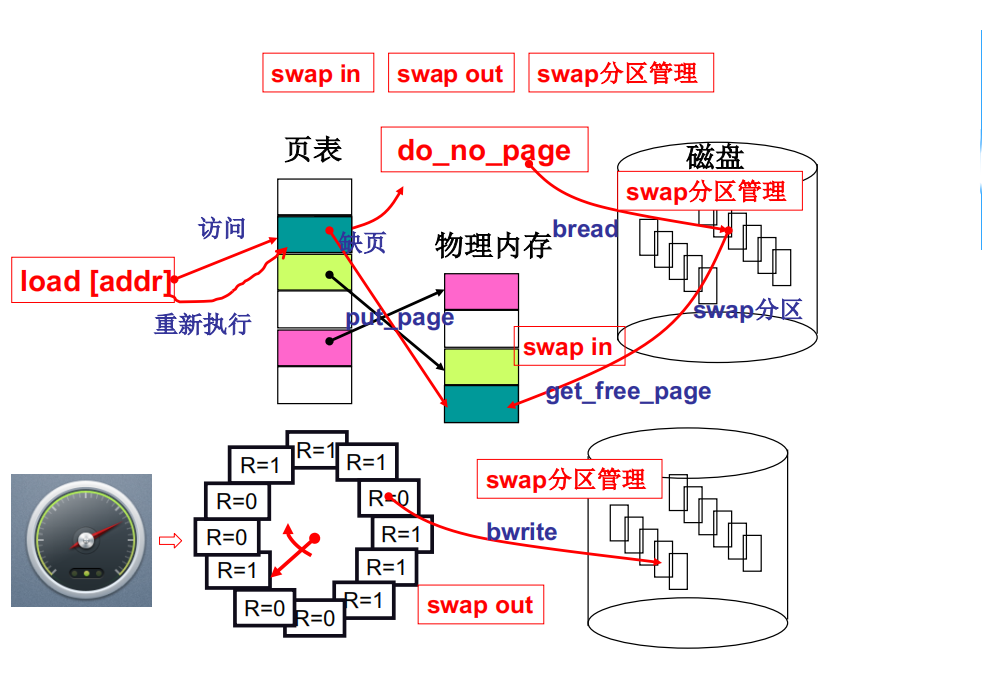
内存换入-请求调页
段页同时存在
用户眼里的内存
用换入、换出实现 “大内存”
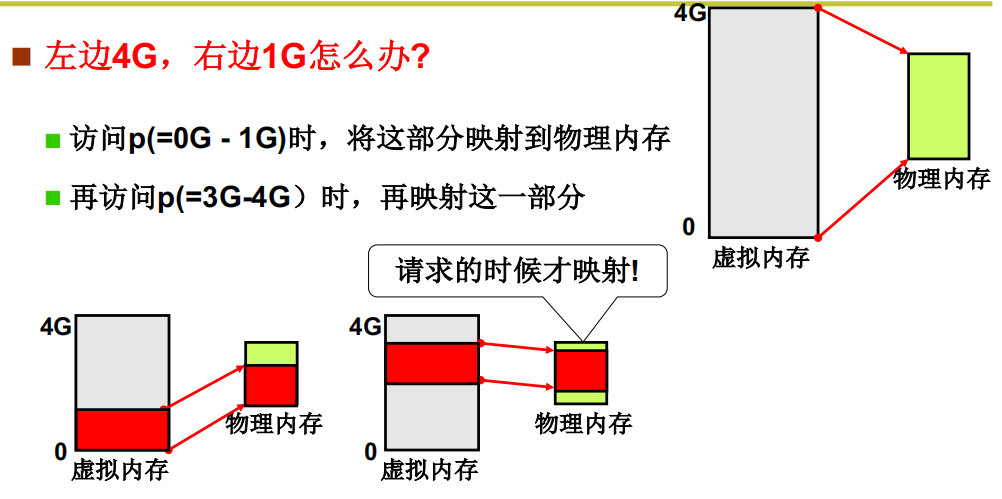
请求调页
请求调页的过程从MMU发现虚拟页面在页表项中的有效位为 0 开始,这个时候 MMU 会向 CPU 发出缺页中断,在一个寄存器的标志位置为1,因为每执行完一条指令都会看一下这个寄存器,因为该标志位已经置为1了,然后进入中断处理程序,从磁盘调入这个页并放入内存中找到的空闲页中(通过调用get_free_page()),做好映射,中断处理程序结束,然后会重新执行那条被中断的指令
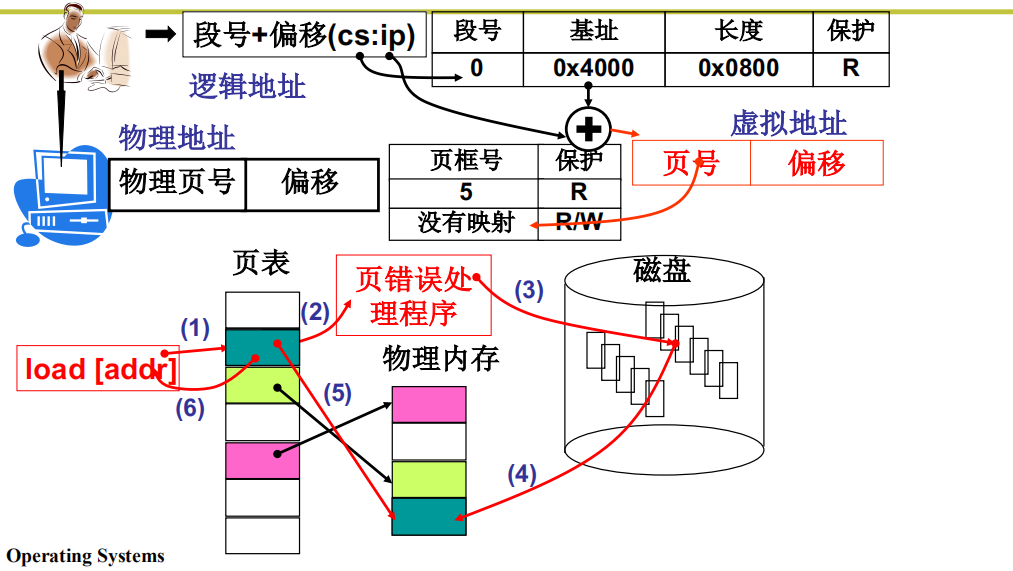
一个实际系统的请求调页

处理中断 page fault

14号中断就是缺页中断,数字14是由计算机硬件电路决定的。page_fault是一段汇编代码,首先取出导致页面错误的类型,判断该页面是没有映射呢还是越级读写。这个错误类型会被压入内核栈中,指令xchgl %eax, (%esp)会将这个错误类型取出来赋给eax寄存器,将来要根据寄存器eax的值来决定到底如何处理这个中断。
然后进行压栈,保存现场,将ds, es赋值为0x10为内核栈的选择子
cr2寄存器保存着页错误的线性地址(虚拟地址),如果是缺页,cr2中存放的就是发生缺页时的虚拟地址,从而知道到底缺了哪个虚拟页,将cr2赋值给edx,并把edx和eax压栈。
进行判断eax标志位,决定调用_do_no_page()(no 对应缺页)还是 do_wp_page()(wp 对应保护,即写一个只读页,之前讨论的写时复制就是通过这个函数来处理的)。
do_no_page()
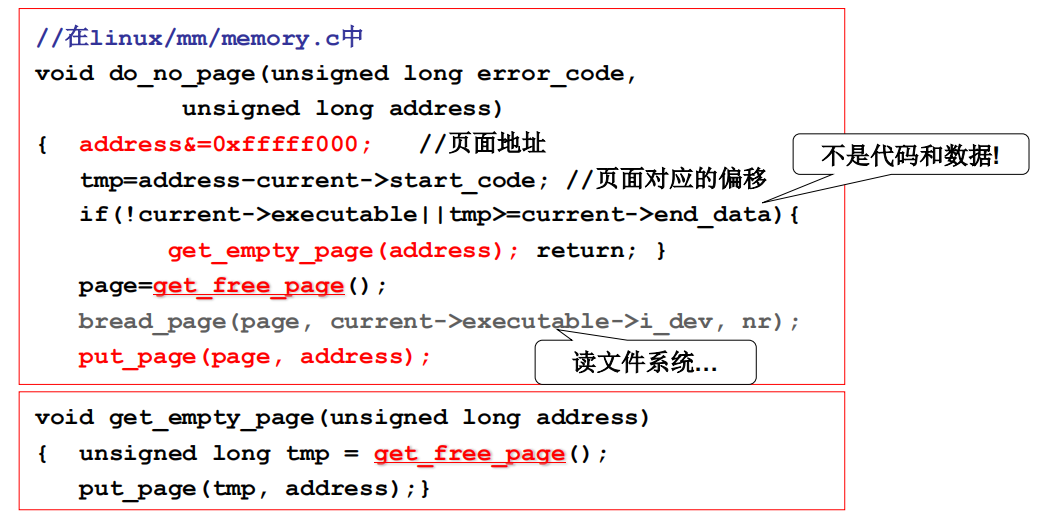
页换入的核心就是由do_no_page完成,不难看出参数address就是用栈传进来的出现缺页的虚拟地址。具体的缺页处理工作就是:算出所缺的虚拟页号,找到一个空闲的物理内存页框,从磁盘上将这个虚拟页读到物理页框中,填写页表完成映射。
address &= 0xfffff000 用来算出虚拟页号
page = get_free_page() 用来获取空闲物理内存页框
bread_page(page, current->executable->i_dev, nr) 用来启动磁盘读写来获取虚拟页面的内容
put_page(page, address) 用来填写页目录项和页表项,完成映射。
put_page
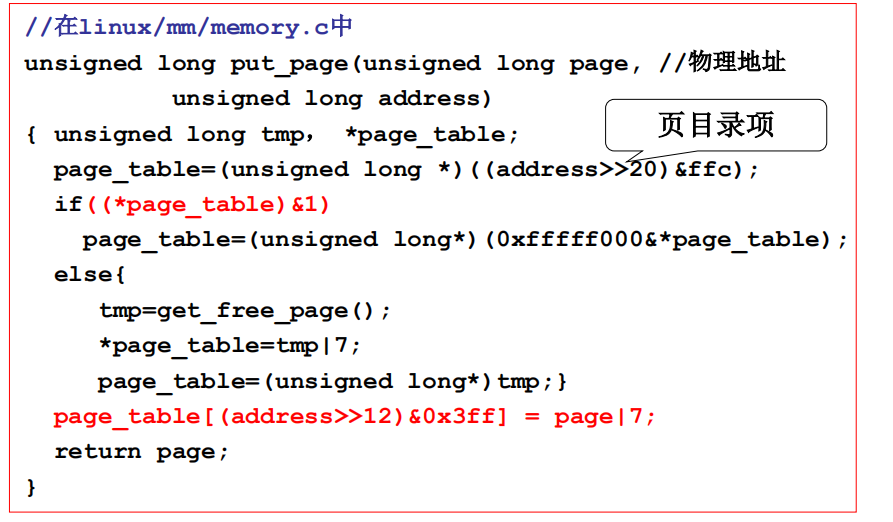
将物理页放入page_table中,建立好映射
内存换出
get_free_page?还是 ?

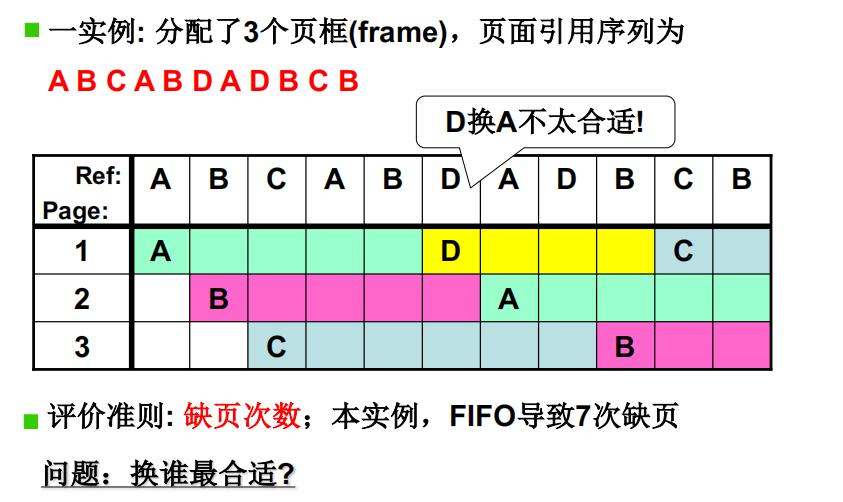
FIFO页面置换
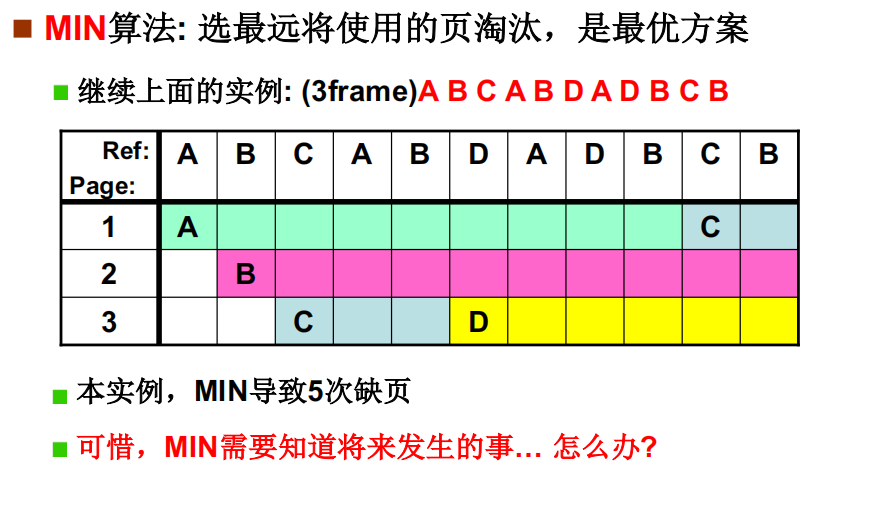
MIN页面置换
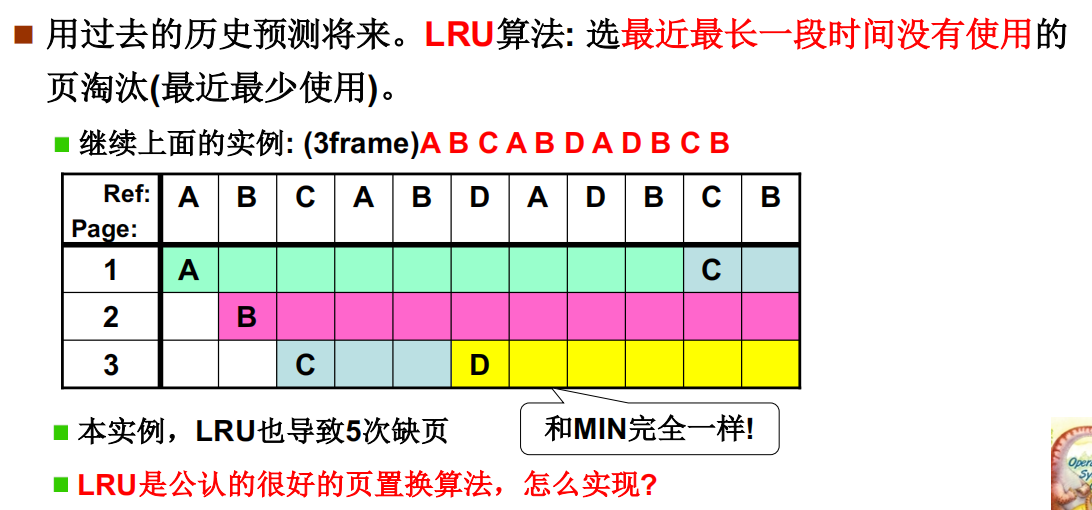
LRU 页面置换算法
LRU的准确实现,用时间戳
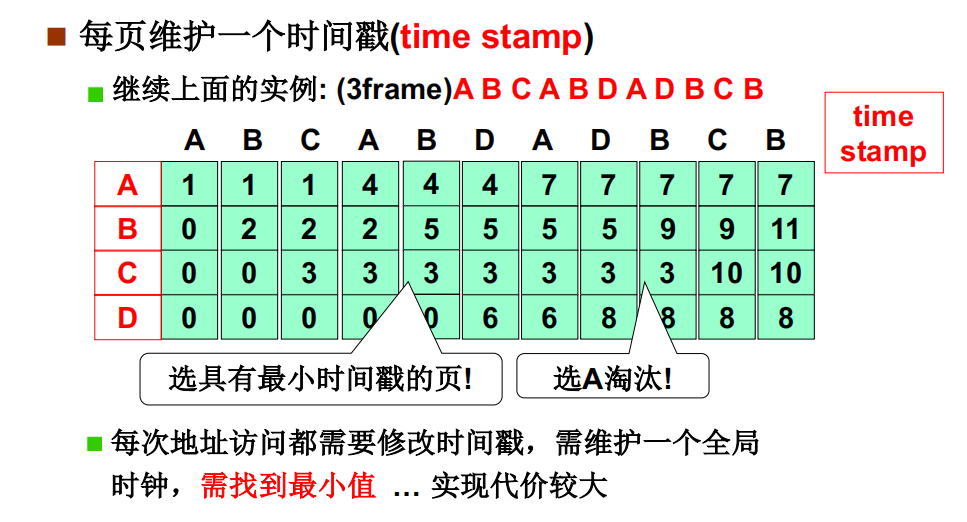
时间戳的数值随着机器的持续运行持续变大,导致存储位数增加,页表长度增大,即使页表项设置得很大,也可能出现时间戳溢出的情况。
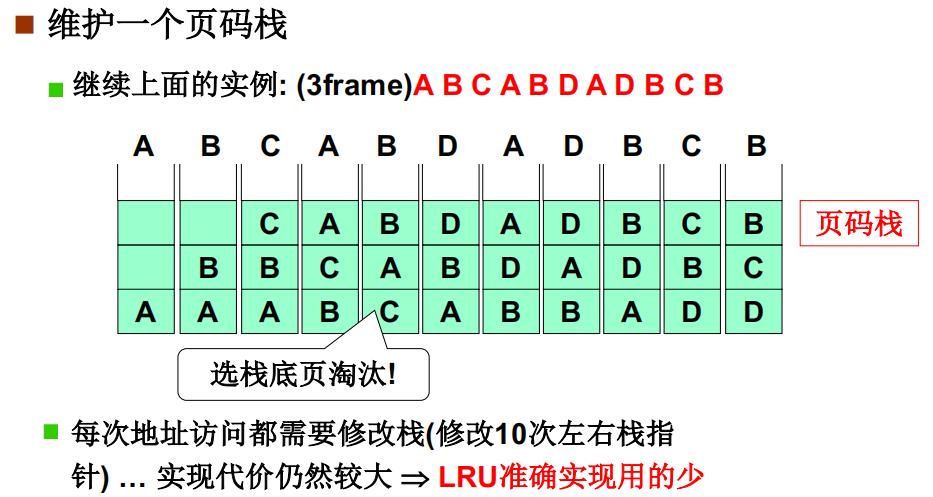
LRU准确实现,用页码栈
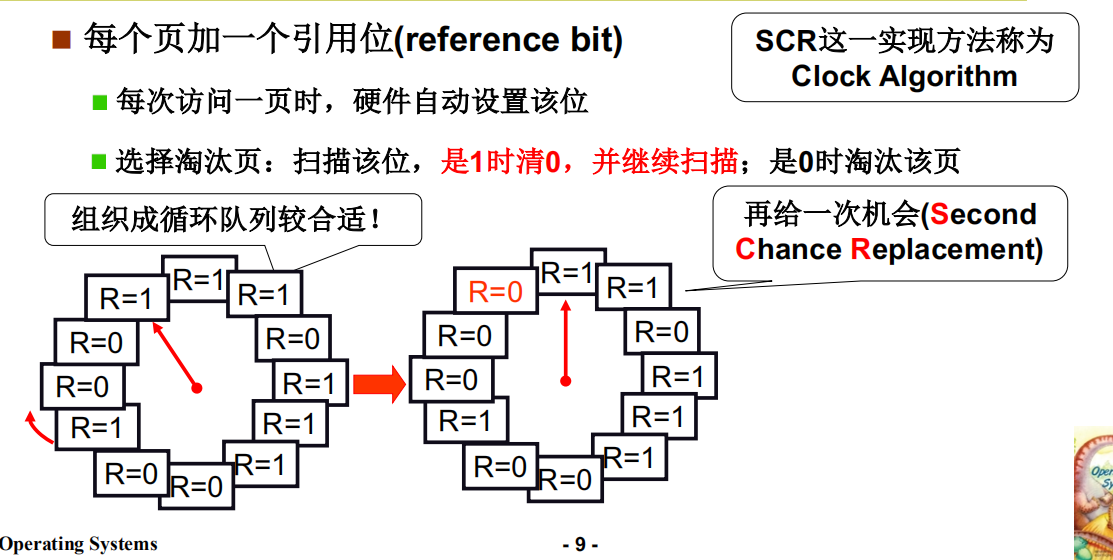
LRU的近似实现 - 将时间计数变为是和否
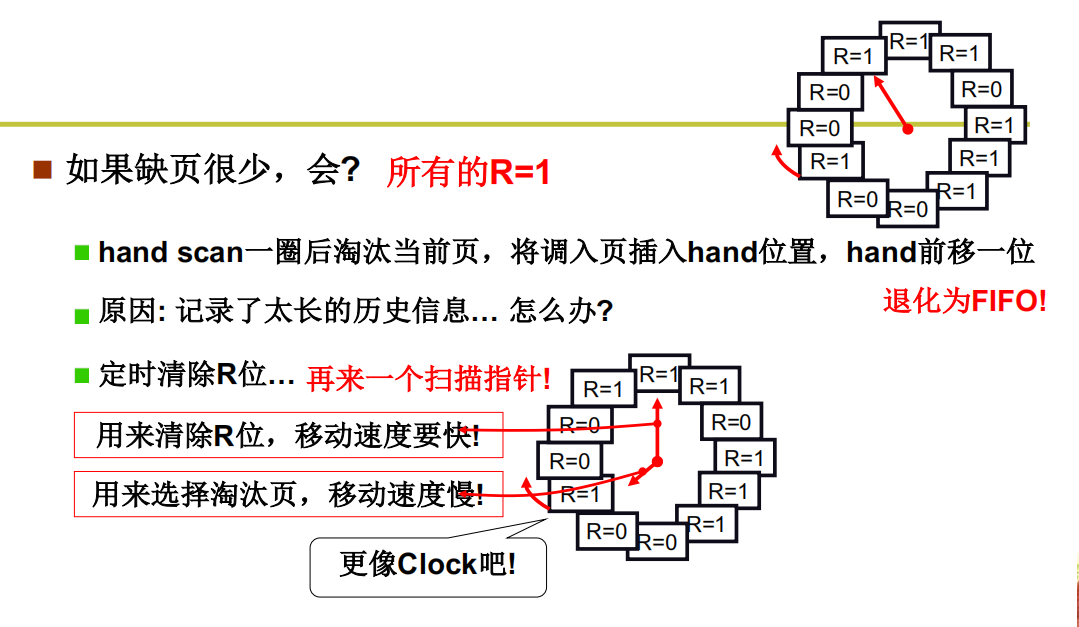
Clock算法的分析与改造
置换策略已经有了,还需要解决一个问题