CPU调度的直观思考
多进程图像与CPU调度
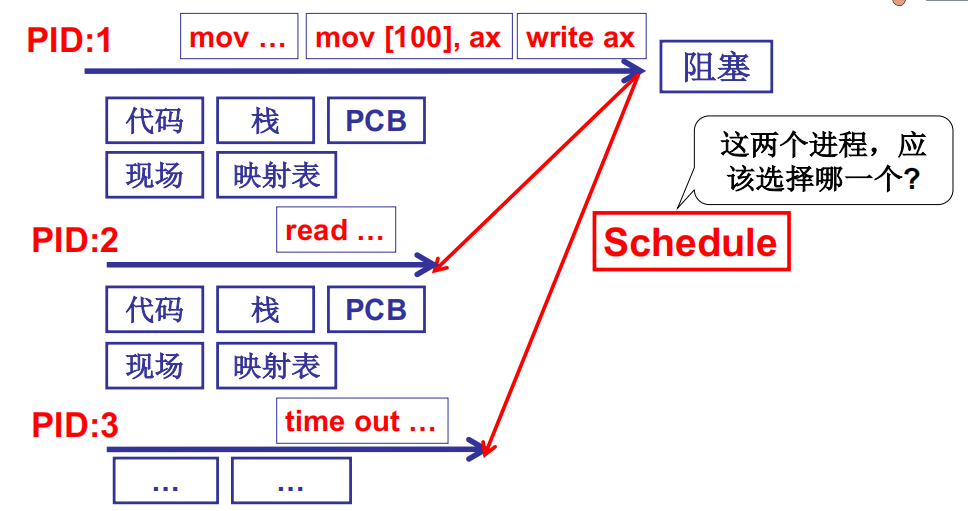
CPU调度(进程调度)的直观想法

先来先服务、短作业优先都有缺点
面对诸多场景,如何设计调度算法

- 比如编译器在执行时希望周转时间短
- word程序运行时不希望周转时间短,但希望响应时间短
总原则:系统专注于任务执行,又能合理的调配任务
调度算法的评测指标
CPU利用率
CPU利用率:指CPU忙碌的时间占总时间的比
$$ 利用率 = \frac{忙碌的时间}{总时间} $$
系统吞吐量
单位时间完成作业的数量
$$ 系统吞吐量 = \frac{总共完成了多少道作业}{总共花费了多少时间} $$
周转时间
作业从被提交给系统开始,道作业完成为止这段时间间隔
周转时间 = 作业完成时间 - 作业提交时间
$$ 平均周转时间 = \frac{各作业带权周转时间之和}{作业数} $$
$$ 带权周转时间 = \frac{作业周转时间}{作业实际运行的时间} = \frac{作业完成时间-作业提交时间}{作业实际运行时间} $$
$$ 平均带权周转时间 = \frac{各作业带权周转时间之和}{作业数} $$
带权周转时间必然 >= 1
带权周转时间与周转时间都是越小越好
对于周转时间相同的两个作业,实际运行时间长的作业在相同时间内被服务的时间更多,带权周转时间更小,用户满意度越高
对于实际运行时间相同的两个作业,周转时间短的带权周转时间更小,用户满意度越高
响应时间
指用从用户提交请求道首次产生响应所用的时间
如何做到合理(需要折中,需要综合)
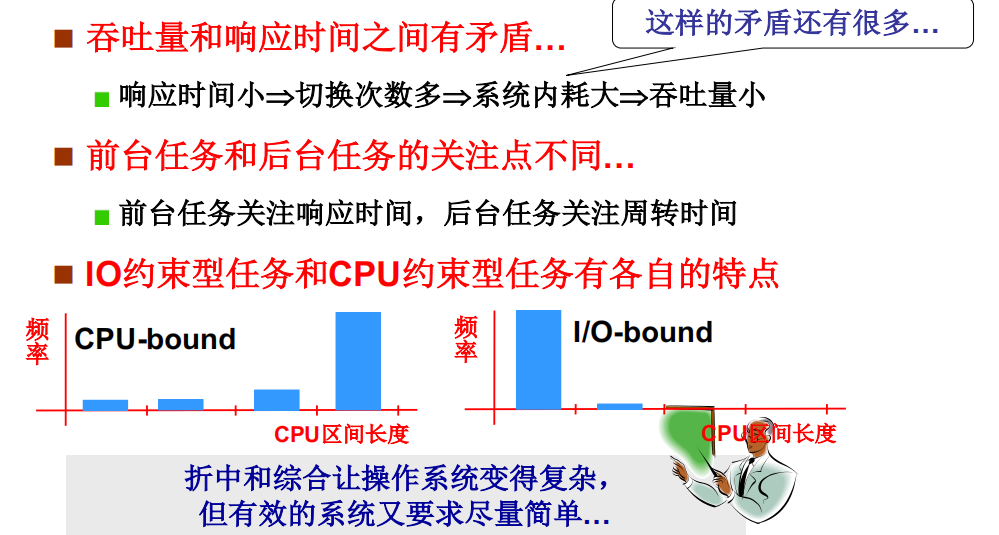
各种CPU调度算法
先来先服务算法(FIFS)
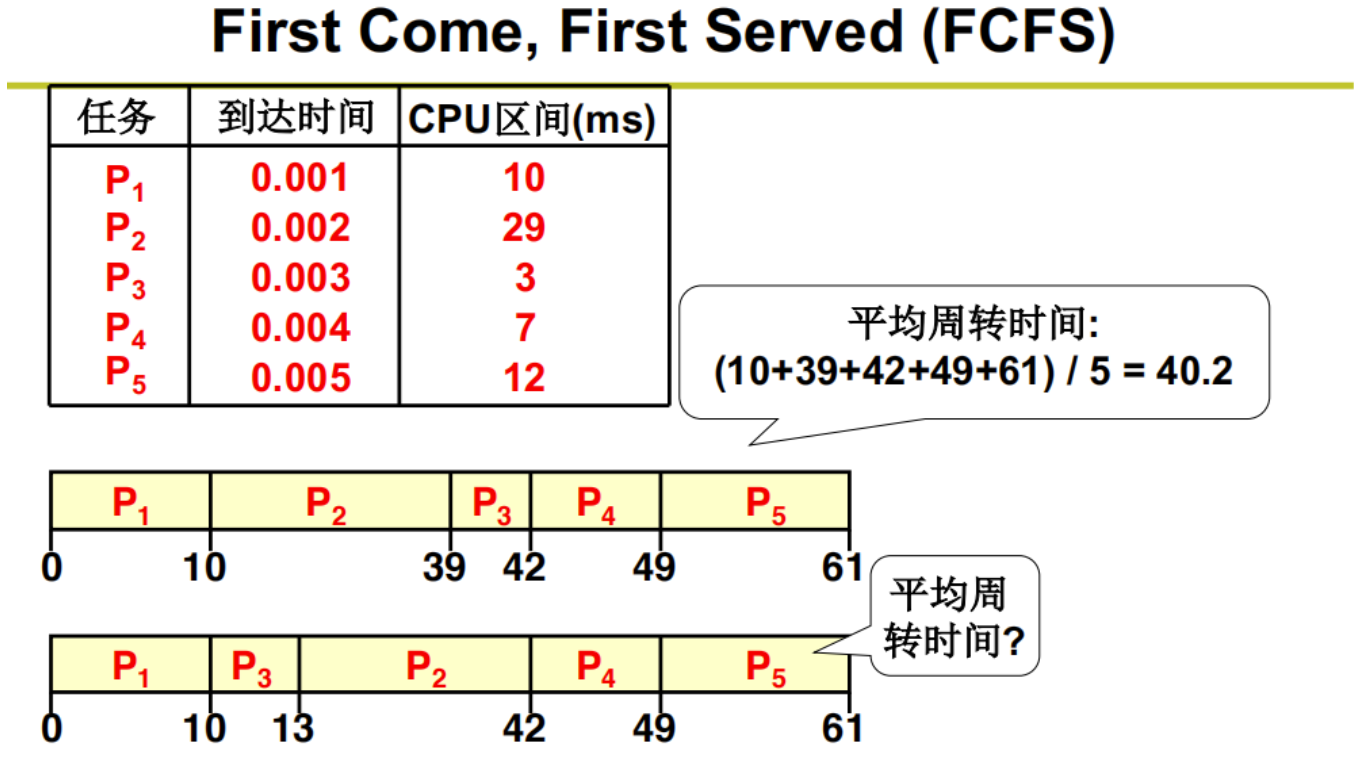
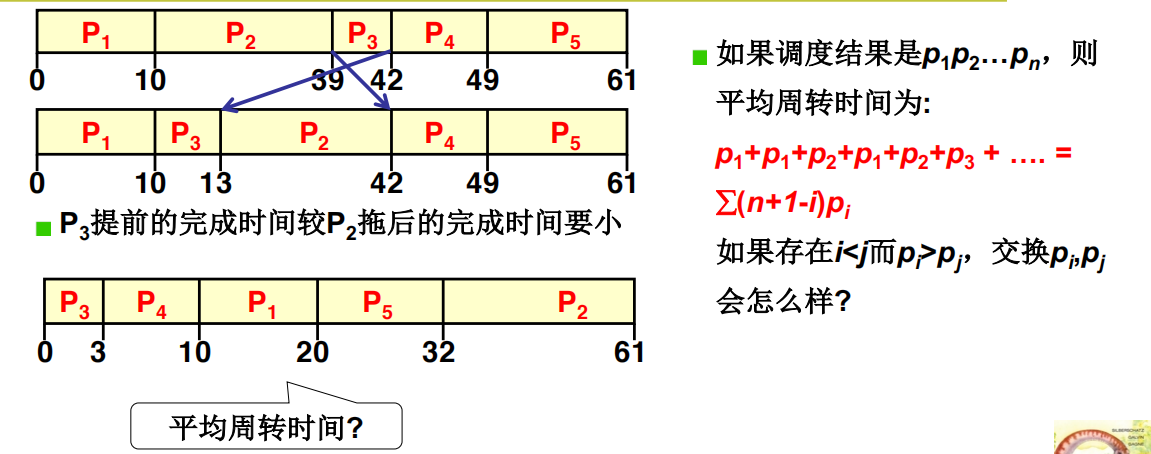
SJF: 短作业优先
使用短作业优先算法可以缩短周转时间,这种方法导致的周转时间是最小的
响应时间该怎么办?(时间片轮转调度)
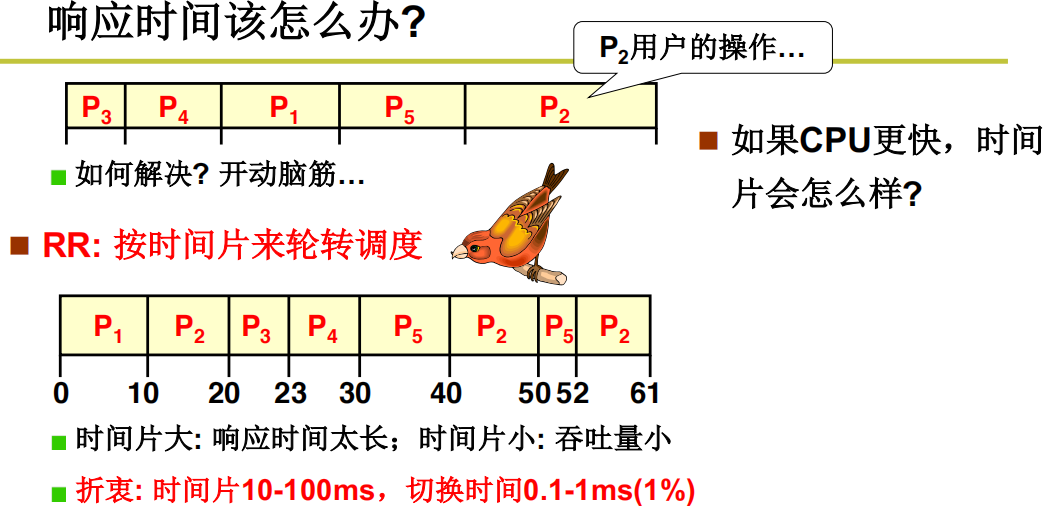
响应时间和周转时间同时存在,怎么办?


一个实际的schedule函数
Linux 0.11的调度程序schedule()
1 | void Schedule(void) { |
counter既指时间片也指优先级
如果所有就绪进程时间片都用完了,进行循环判断:
如果是就绪任务中的进程counter置为初值
如果是阻塞进程则 counter = counter/2 + priority
执行完IO阻塞的进程counter回来的时候一定会变大,优先级会提高,时间片也会增加
counter的作用:时间片
在时钟中断中, 每次让时间片减一,如果减为零,则进行调度
1 | void do_timer(...) { //在kernel/sched.c中 |
1 | _timer_interrupt: //在kernel/system_call.s中 |
1 | void sched_init() { |
counter是典型的时间片,所以是轮转调度,保证了响应
counter的另一个作用:优先级
1 | while(--i) { |
找到counter最大的任务调度,counter表示了优先级
1 | if(c) break; |
counter代表的优先级可以动态调整
counter作用整理
- counter保证了响应时间的界
- 经过IO之后,counter会便大; IO时间越长,counter越大,照顾了IO进程,变相照顾了前台进程
- 后台进程一直按照counter轮转,近似了SJF调度
- 每个进程只用维护一个counter变量,简单、高效
CPU调度:一个简单的方法折中了大多数任务的需求,这就是实际工作的schedule函数
