多进程图像

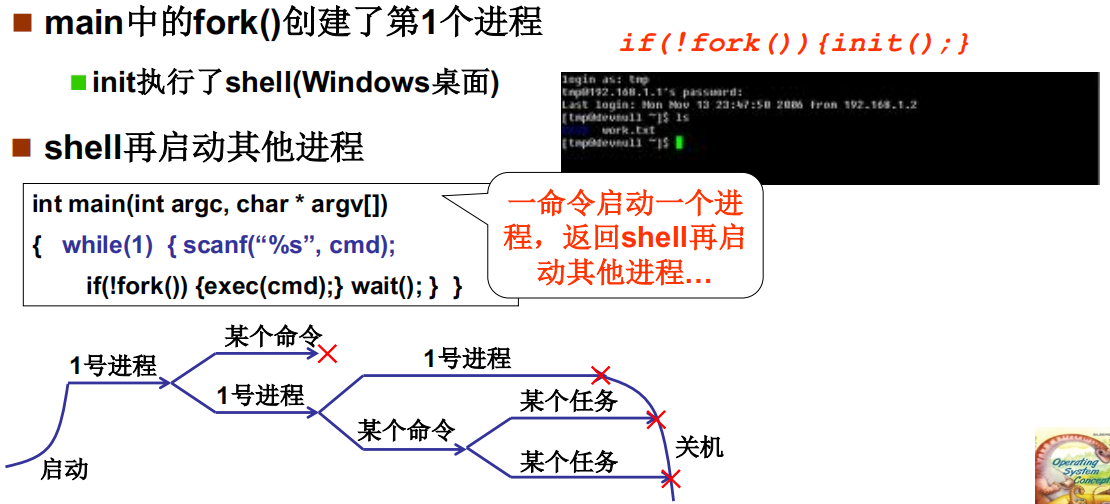
多进程图像从启动开始到关机结束
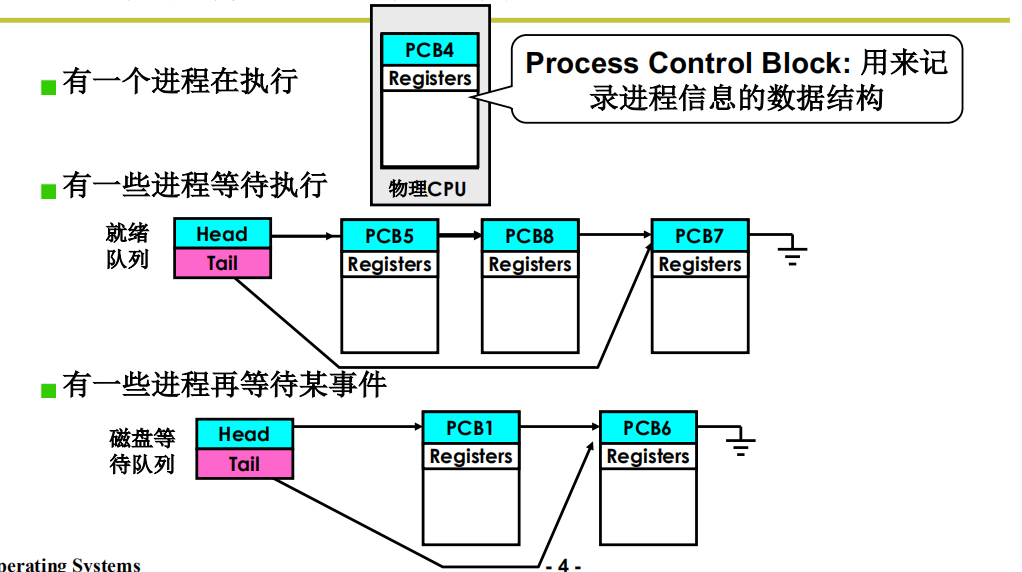
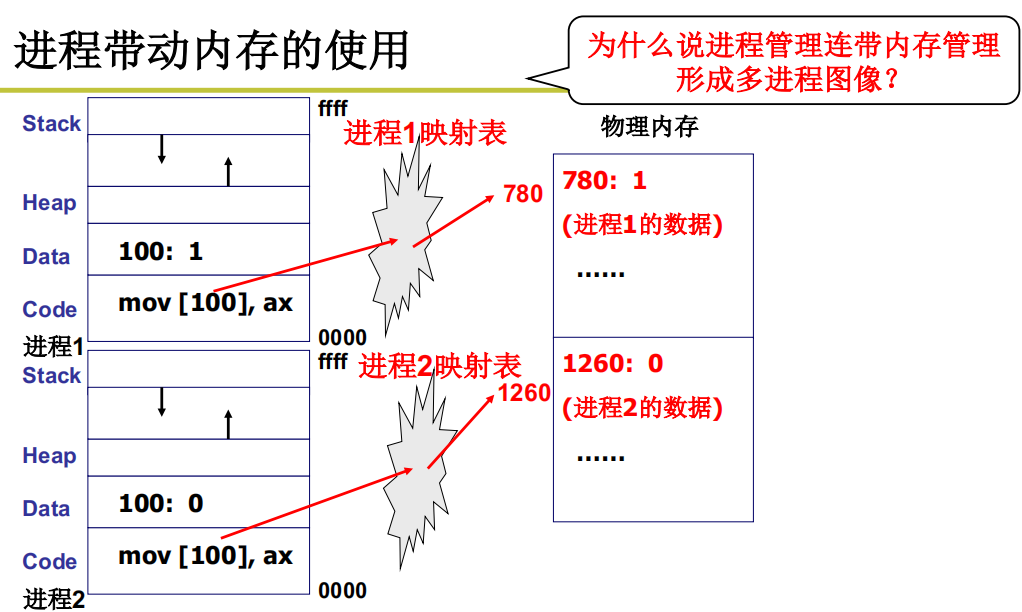
多进程图像如何组织
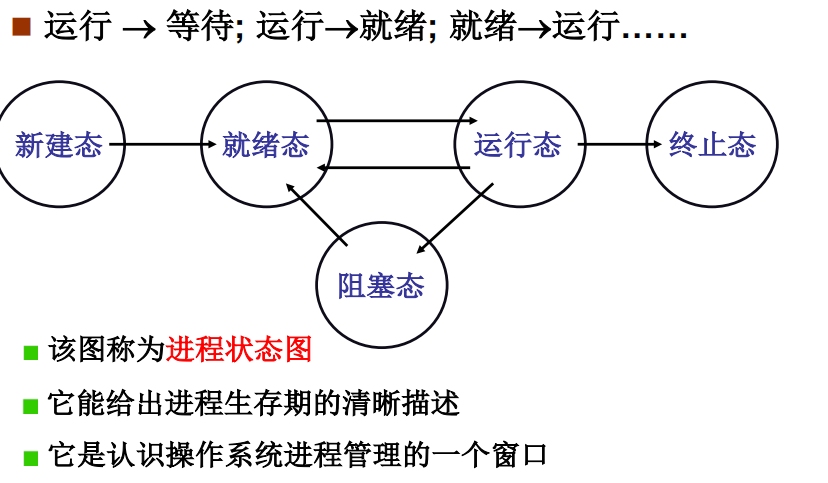
多进程如何交替

交替的三部分:队列操作+调度+切换
多进程如何影响?

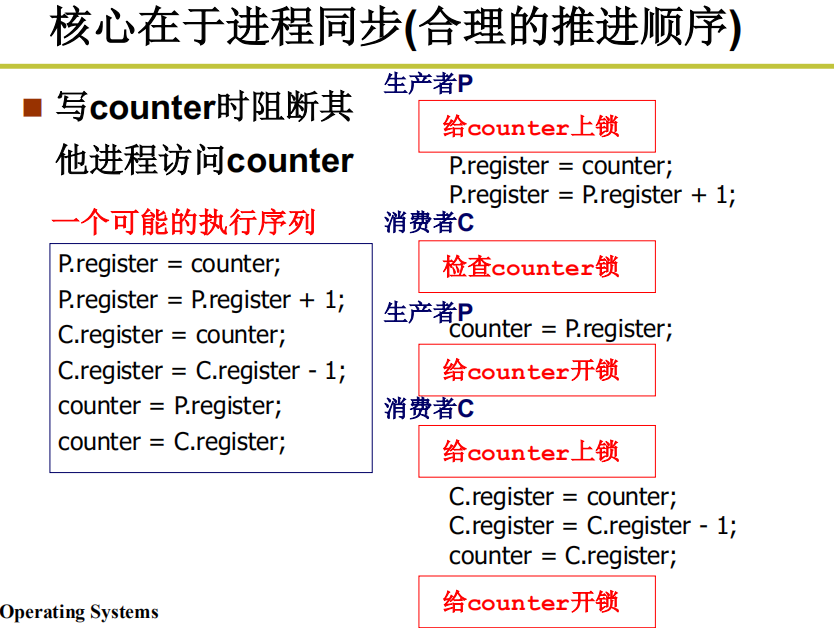
多进程如何合作
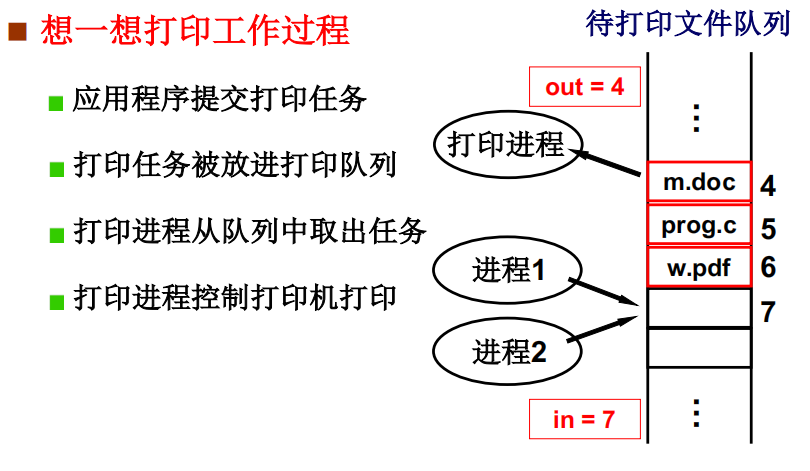
生产者-消费者示例



用户级线程(L10)
是否可以资源不动而切换指令序列
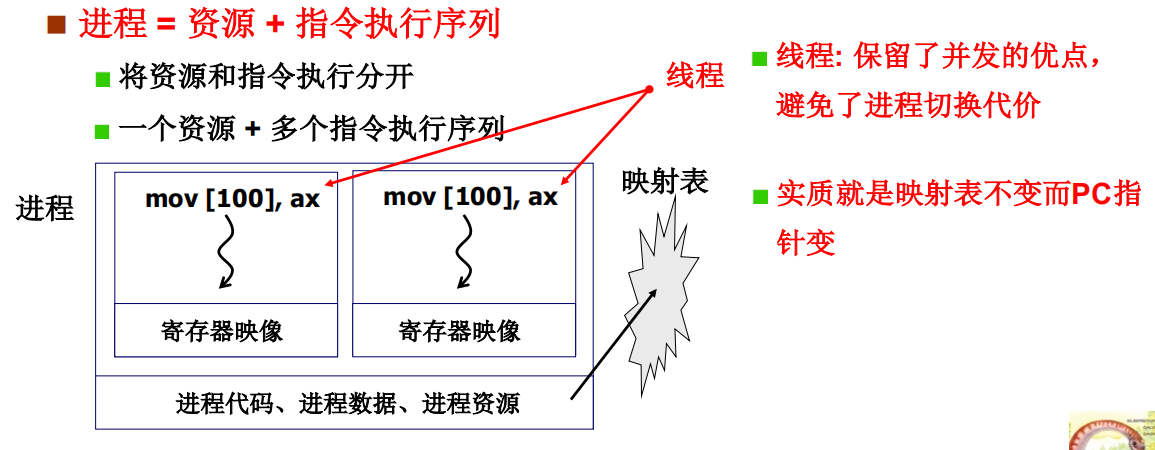
多个指令序列 + 一个地址空间是否实用


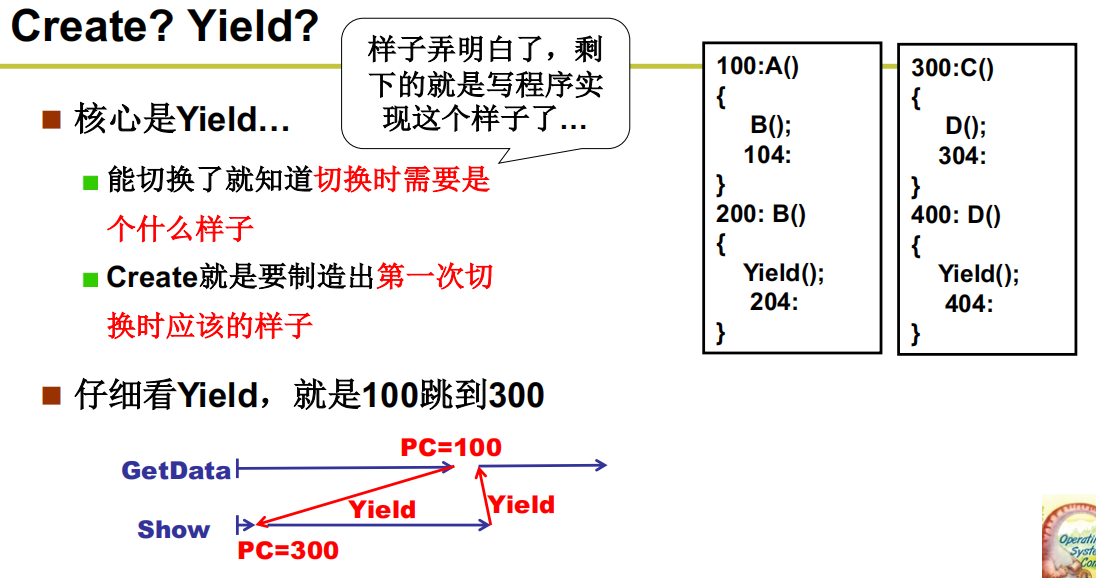
Create Yield
两个执行序列与一个栈
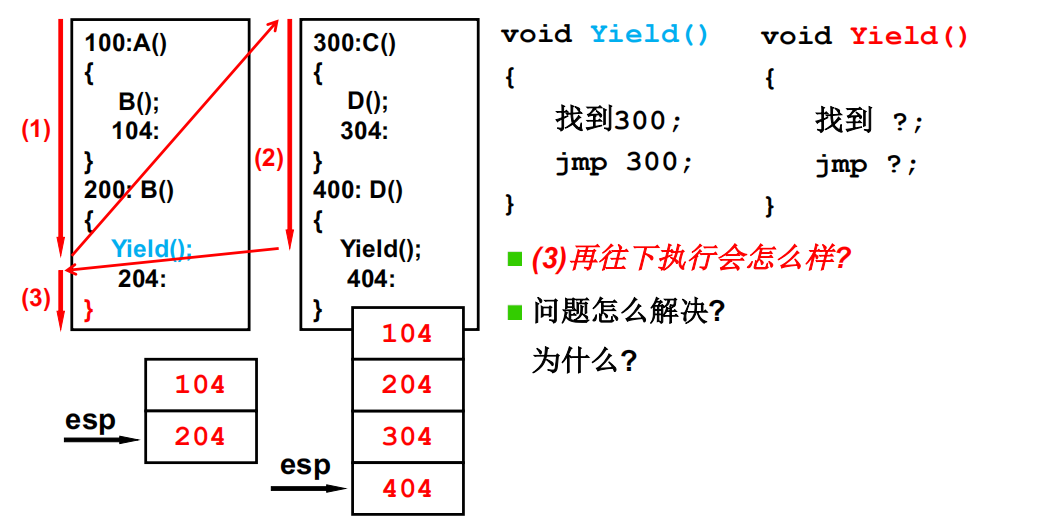
从一个栈到两个栈

这段太妙了吧,Yield()最后要跳转到204地址处,但此时如果适用
jmp 204会导致返回后TCB1的栈中仍然存放着204的地址,则在下次ret后会再跳转到204地址处,导致重复执行,所以应该把jmp 204去掉,因为此时保存的栈已经是TCB1的栈,Yield() 执行ret时就自动跳转到 204 地址处,并且弹出204。
两个线程的样子:两个TCB、两个栈、切换的PC在栈中

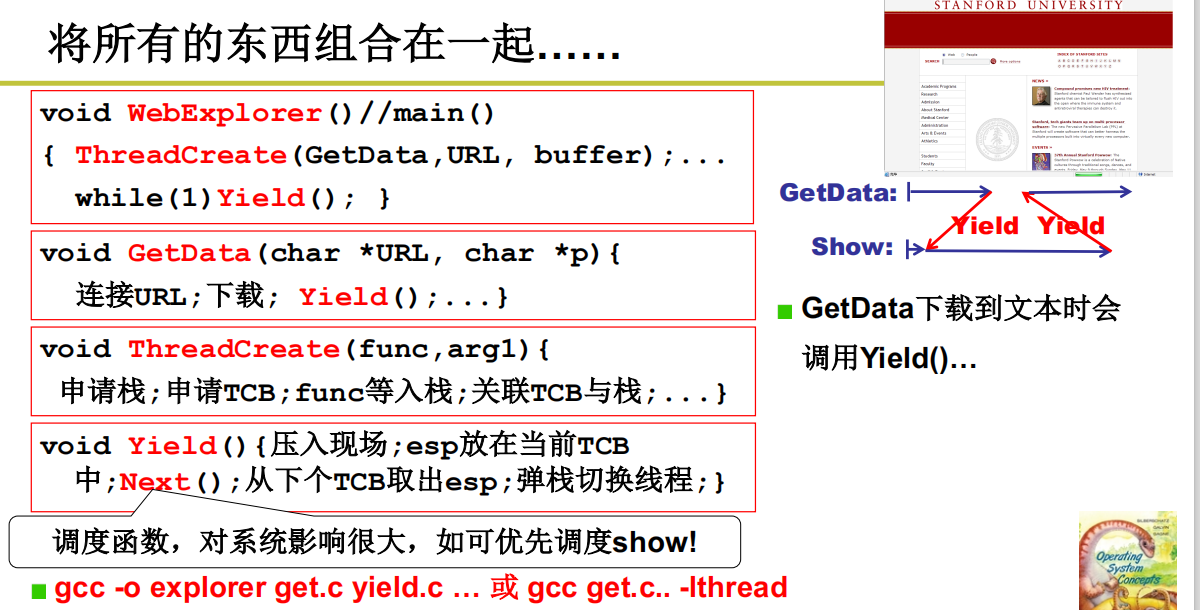
为什么说是用户级线程-Yield是用户级线程
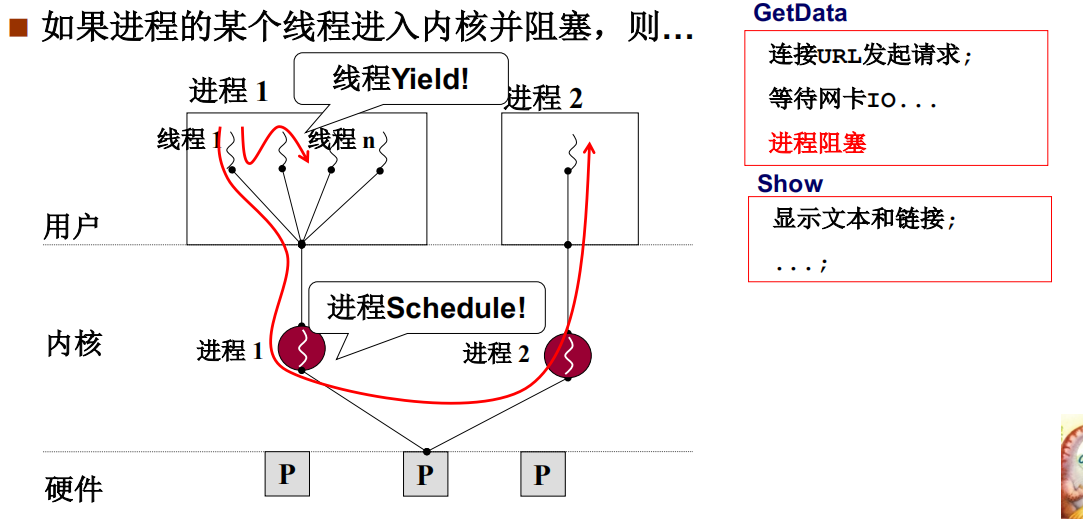
核心级线程
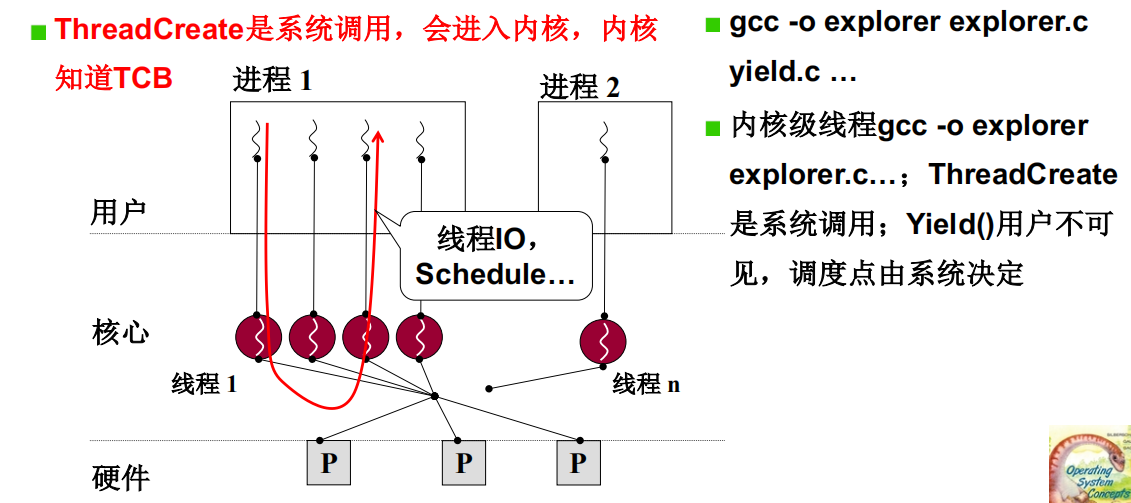
内核级线程
开始核心级线程
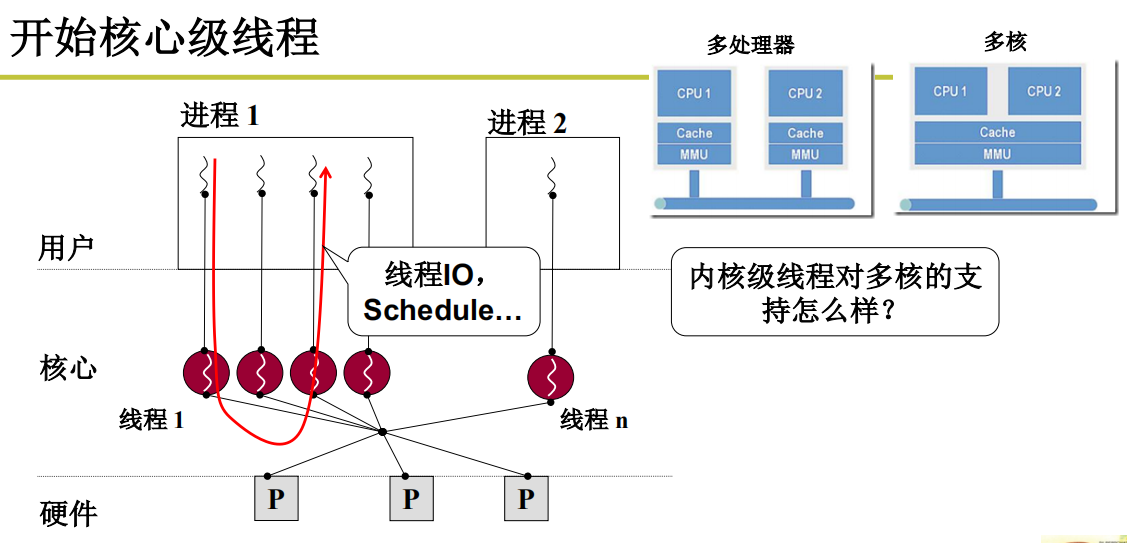
只有内核级线程才能多核并行,充分发挥多核的价值
- 多进程在多核上的情况,关键在于
Cache和MMU是否共享
和用户级相比,核心级线程有什么不同
内核级线程就是要让内核态内存和用户态内存核作创建一个指令执行序列,内核级线程的TCB等信息是创建在操作系统内核中的,操作系统通过这些数据结构可以感知和操纵内核级线程。
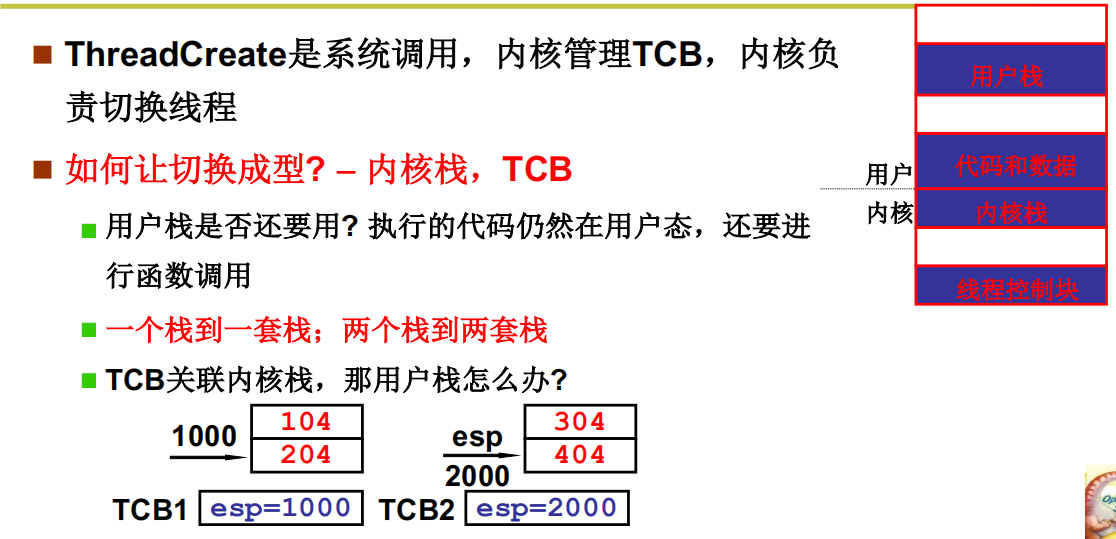
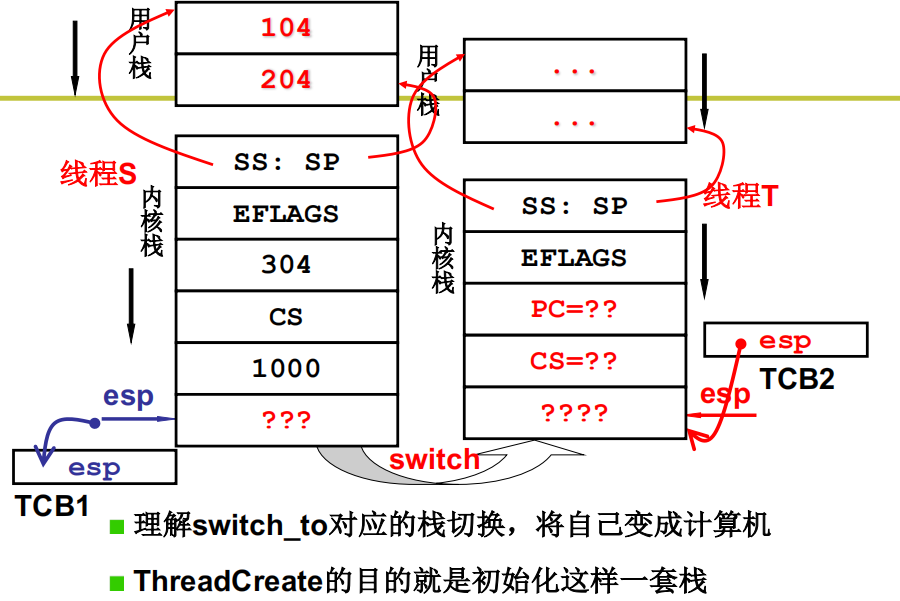
用户栈和内核栈之间的关联
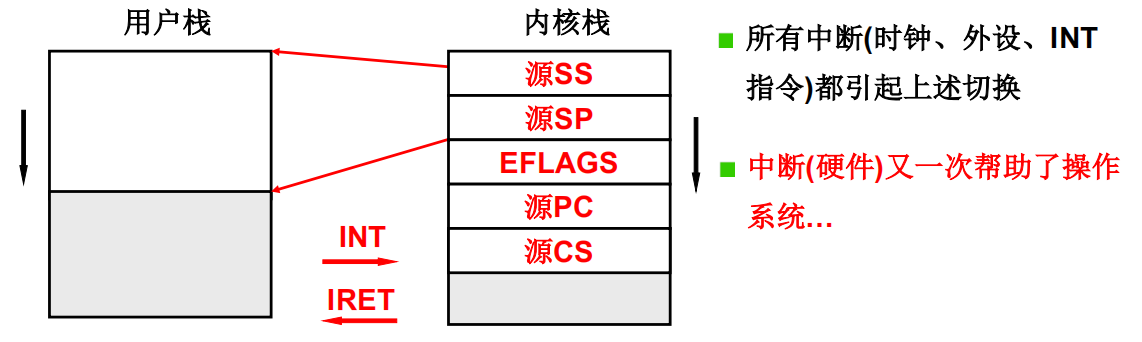
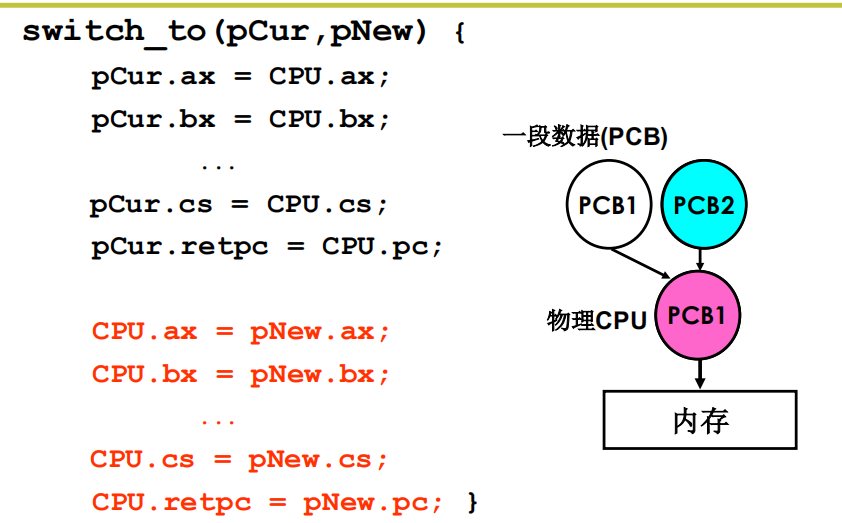
开始内核中的切换:switch_to
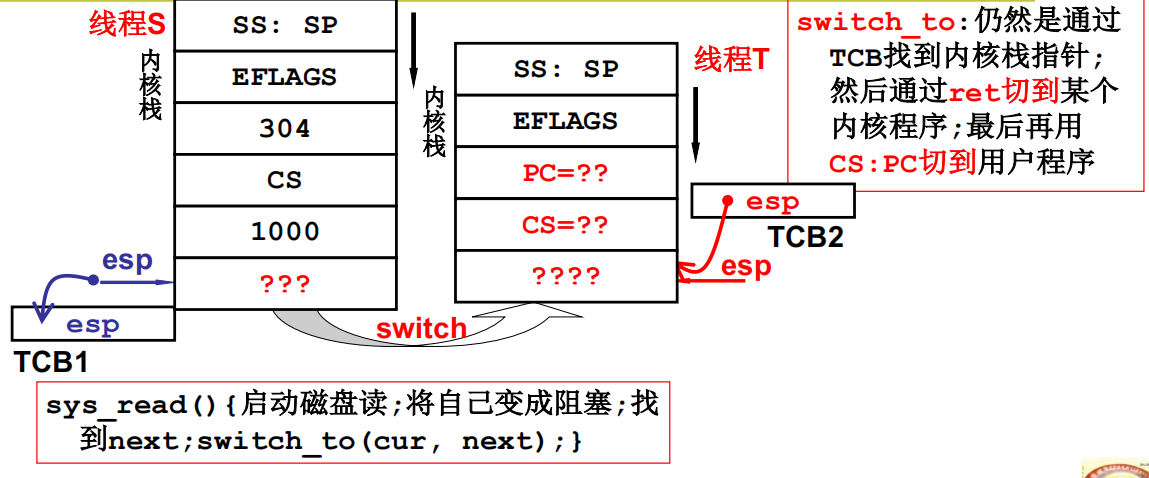
内核线程switch_to的五段论

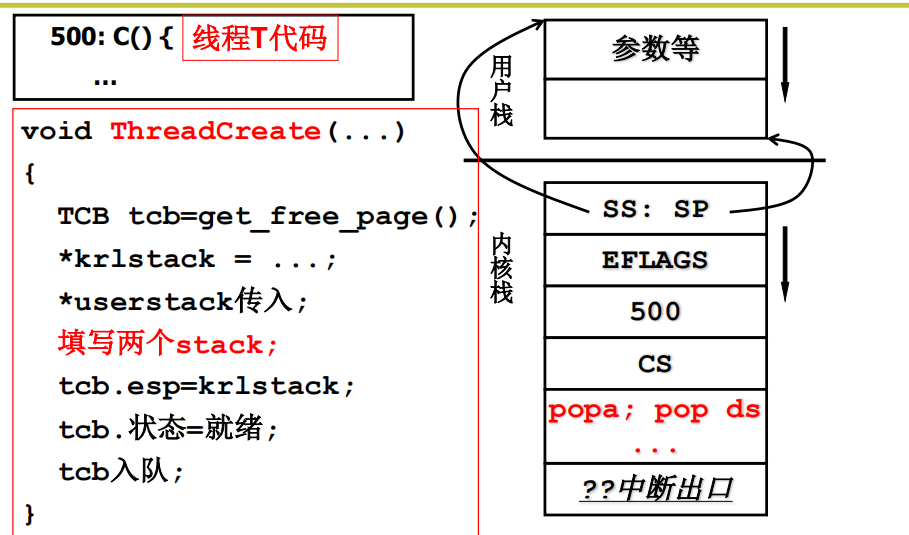
ThreadCreate()
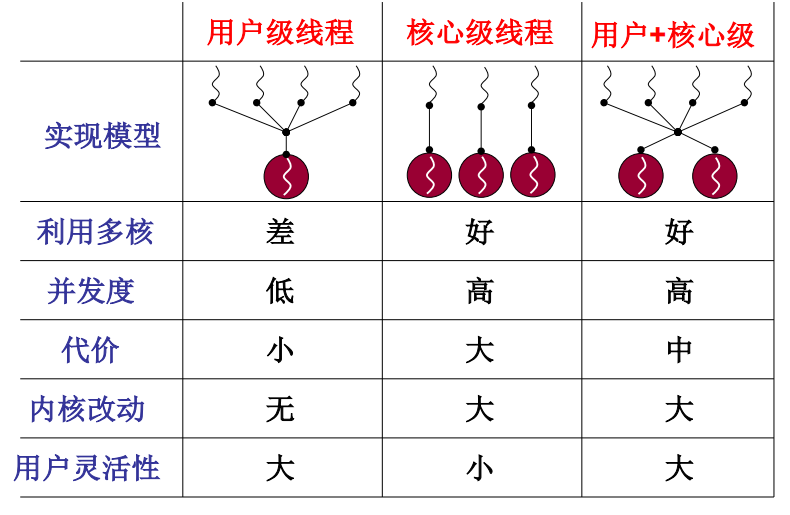
用户级线程、核心级线程的对比
内核级线程代码实现
核心级线程的两套栈,核心是内核栈
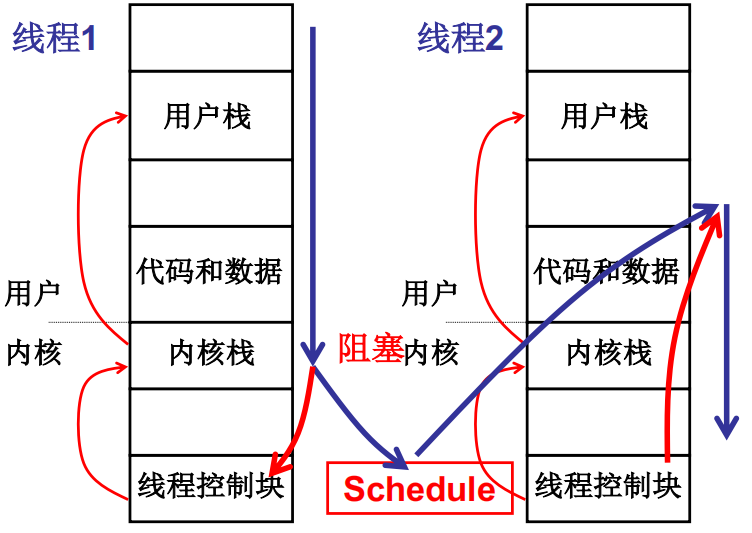
核心级线程的实现,关键在于两套栈之间的切换,线程1通过init指令进入内核执行,中途可能调度到另外一个线程执行,首先TCB进行切换,这时候TCB中有内核栈的指针,这样内核栈就切换过来了,在内核执行完后通过 iret用户栈跟着也切换过来了。
用户级线程切换的核心是根据存放在用户程序中的TCB找到用户栈,通过用户栈切换完成用户级线程的切换,整个切换过程通过调用
Yield()函数引发内核级线程切换的核心是首先进入操作系统内核并在内核中找到线程TCB,进而根据TCB找到线程的内核栈,通过内核栈切换完成内核级线程的切换,整个过程由中断引发
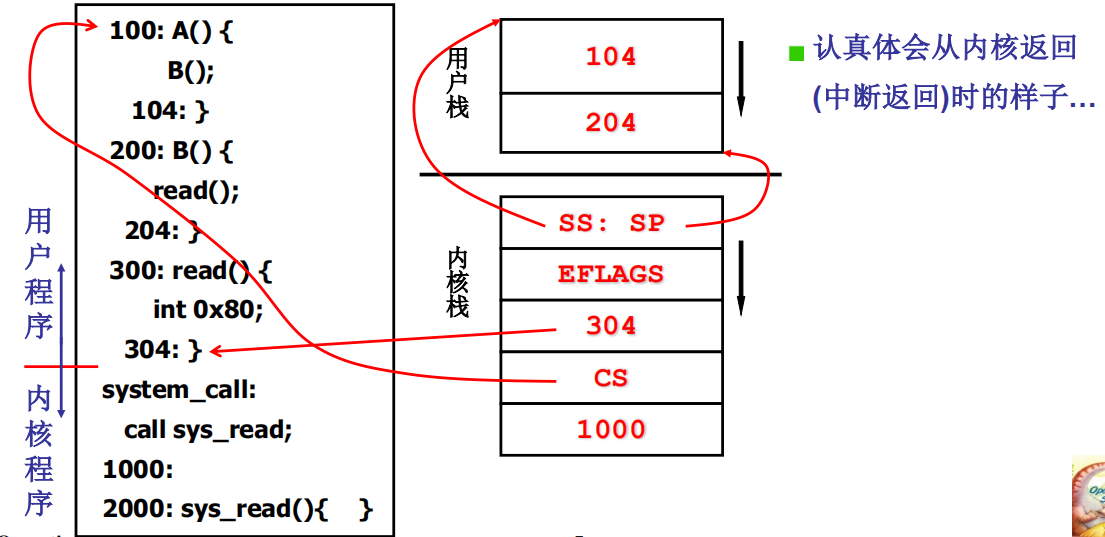
进入内核过程(某个中断的开始)
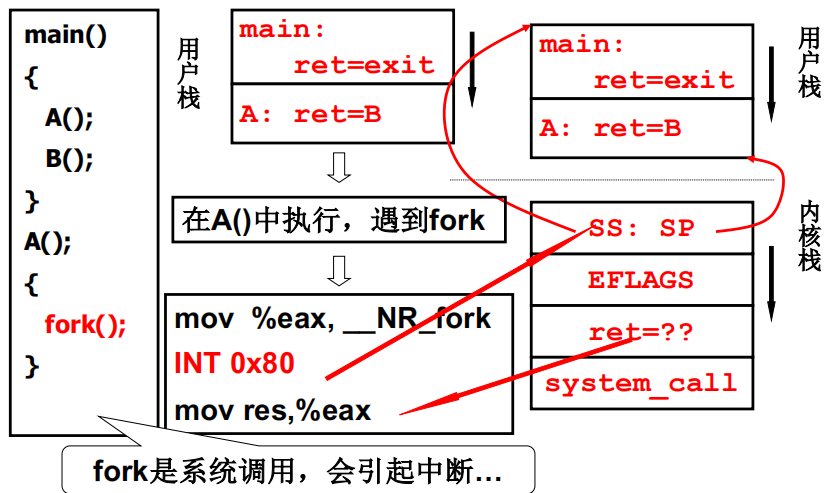
注意:这里的将system_call压入核心栈的目的与之前用户线程的yield类似,这样在int 0x80执行完后会跳转到 sytem_call去执行,然后pop()一下
内核级线程切换过程五段论(重要)
1.中断进入
中断进入,就是int指令或其它硬件中断的中断处理入口,核心工作就是记录当前程序再用户态执行的信息,如当前使用的用户栈、当前执行程序执行位置、当前执行的现场信息等。其中用户栈地址 SS:ESP 和 PC 指针信息CS:EIP已经由中断处理硬件 自动 压入当前线程对应的内核栈中,只有当前的执行现场信息没有保存。所以在进入中断处理程序的开始处需要编写代码保护用户态程序当前的执行现场(保护在内核栈中)。以int 0x80为例,应该在中断处理程序system_call的开始执行处执行下面的代码,即中断进入代码:
1 | push %ds |
以上代码用作保护用户态程序执行现场。接下来就可以使用这些寄存器来执行内核态中断处理程序了,如用movl $0x10, %edx, mov %dx, %ds, mov %dx, %es来将段寄存器、ES寄存器设置为内核数据段选择子,这样以后再访问的数据就是内核数据了。
2.调用schedule
在中断处理程序中,如果发现当前线程启动了磁盘读写等操作,即发现当前线程应该让出CPU时,系统内核就会调用schedule()函数来完成TCB的切换。具体做法很简单,例如在向磁盘发出读写指令以后,将当前线程(可以定义一个内核全局变量current来指向当前线程的TCB)的状态修改为阻塞,并将current添加到一个等待某个磁盘块读写完成的等待队列链表上,接下来调用schedule(),实现TCB的切换。
为了完成TCB的切换,schedule()函数首先从就绪队列中选取下一个要执行线程的TCB,用next指针指向这个TCB,利用current和next指针指向的信息就可以开始内核级线程的切换的第三个阶段。
3.内核栈的切换
第三个阶段就是内核栈的切换,具体来说,就是将当前的ESP寄存器存放在current指向的TCB中,再从next指向的TCB中取出esp字段赋值给ESP寄存器。
4.中断返回
与内核级线程切换的第一阶段相对应,在这一个阶段中,要将存放在下一个线程的内核栈(此时内核栈已完成切换)中的用户态程序执行现场恢复过来,这个现场是这个线程在切换出去时由中断入口程序保存的。仍然以上面给出的system_call为例,此时要用pop将压在内核栈中的寄存器恢复出来,中断返回代码如下:
1 | popl %ebx |
5.用户栈切换
实际上就是切换用户态程序PC指针及相应的用户栈,即需要将CS:EIP寄存器设置为当前用户程序的执行地址,将SS:ESP寄存器设置为当前用户栈地址即可,而这两个信息现在就存在下一个线程的内核栈中,只要执行 iret 指令就可以完成这个切换了。
切换五段论中的中断入口和中断出口
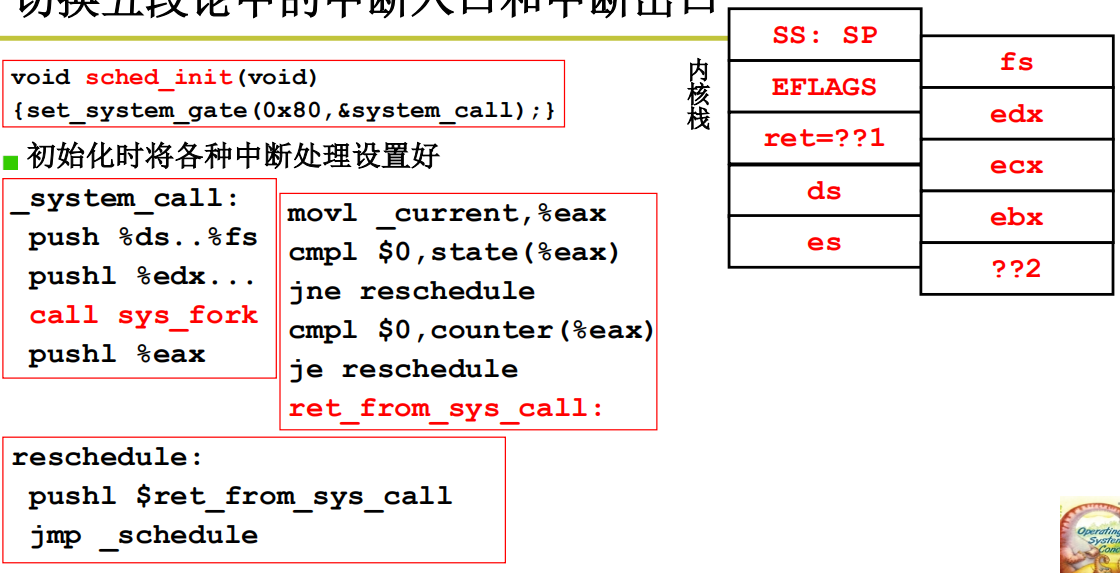
内核栈中的ret指cs, eip
在_system_call中,首先要将用户态寄存器等信息通过压栈的方式记录下来,然后执行sys_fork 调用__system_call_table中的表进入到内核具体处理sys_fork, 进入到内核中,然后判断状态是不是阻塞,如果阻塞,则进行reschedule引起内核级线程的切换,如果没有阻塞,再看时间片是否用光,如果用光了也要进行切换,切换完成以后,跳回来执行ret_from_sys_call,执行中断返回,弹出响应的用户信息,中断返回后从内核栈到用户栈。
切换五段论中的schedule和中断出口
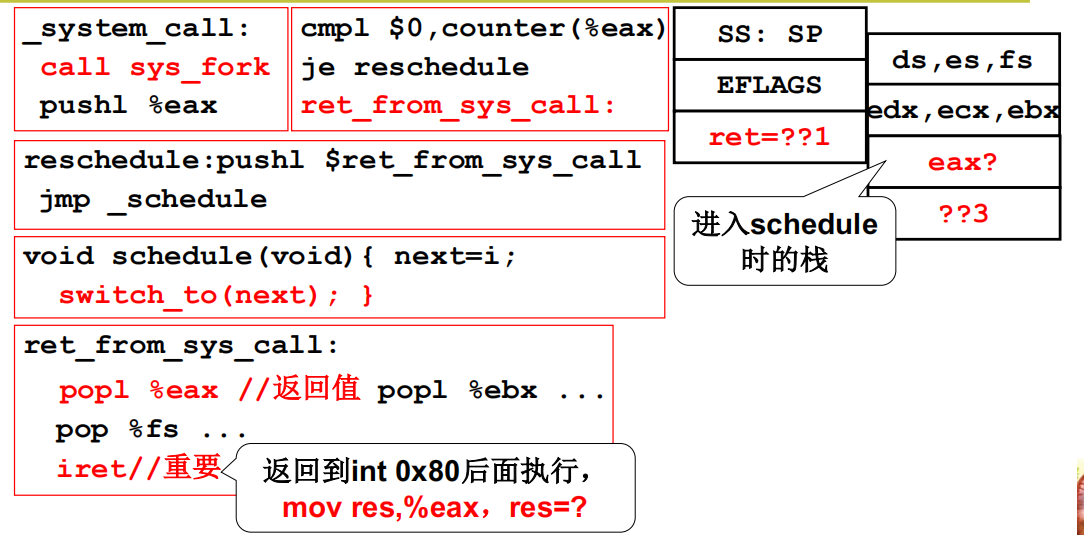
切换五段论中的switch_to

ljmp %0是一个长跳转指令,具体解释如下:
- 准备工作:将当前CPU所有寄存器信息拷贝到当前
tr寄存器通过查GDT表指向的原tss段,即将上一个任务的执行现场保存一份到原tss中 _TSS(n)已经在长跳转的操作数中,通过TR查表找到新的tss,然后将里面的寄存器信息赋给当前CPU寄存器中。
这种方法通过一条指令切换大量的寄存器所以比较慢,且不能进行指令流水,所以我们需要将这种方法改成基于栈的做法
ThreadCreate()

将内核栈的内容全部作为_copy_process的参数。
copy_process的细节:创建栈
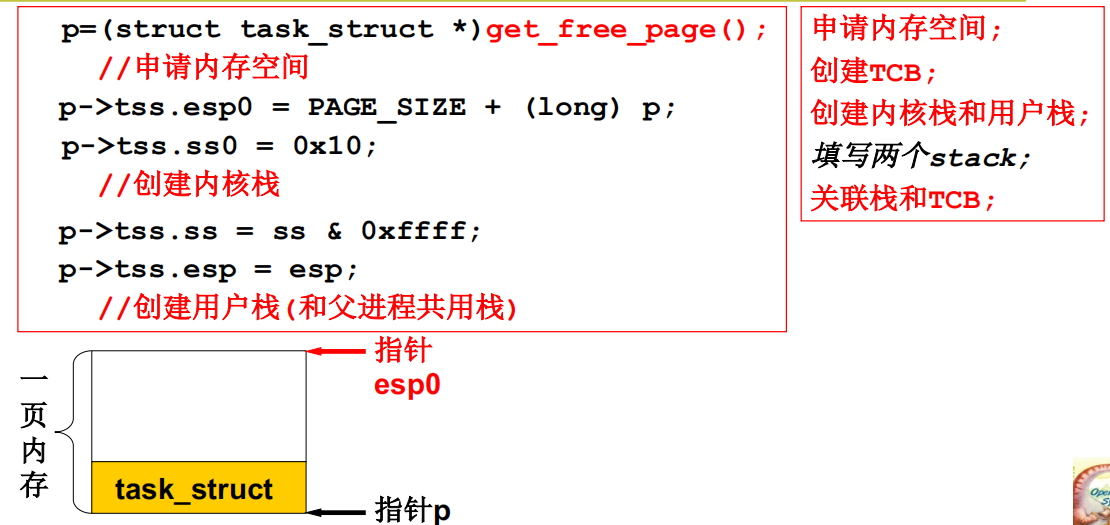
copy_process的细节:执行前准备

这里将 p->tss.eax 置为 0, 意味着当以后 fork()回去后返回值为 0, 执行mov res, %eax ,
回顾之前调用fork()的结构:父进程返回值不为零,而子进程为0
1 | if(!fork()) { |
整理一下,tss初始化好了,可以完成切换,用户栈用父进程同样的栈,核心栈和TCB创建好新的内容,并且关联好相应内容。
第三个故事:如何执行我们想要的代码
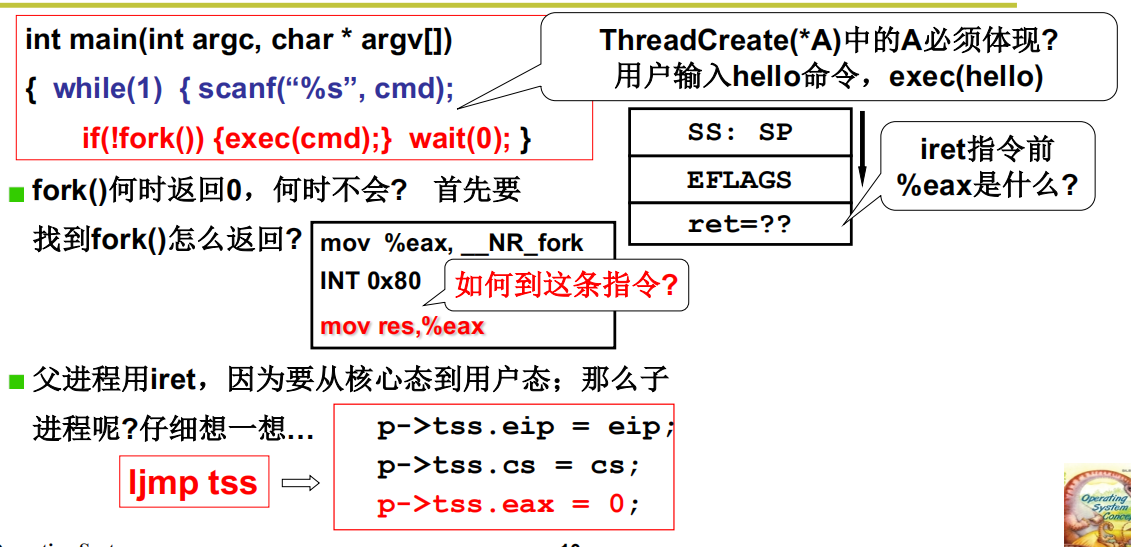
结构:子进程进入A,父进程等待

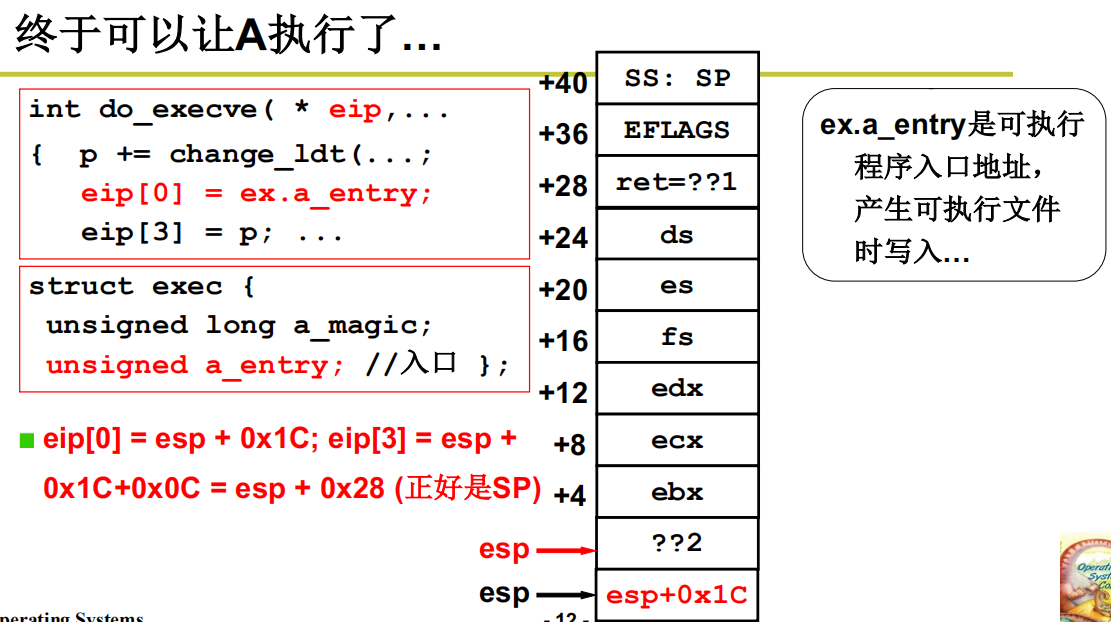
这时候将 eip[0] 赋值为你想执行的程序的地址,eip[3] 赋值为新的栈地址,就可以在 iret时切换到你想执行的用户程序了