内核链表
内核链表定义
内核中如下定义双向链表
1 | struct list_head { |
如何引用已定义的链表
1 | struct my_list { |
list字段:隐藏了链表的指针特性,但正是它,把我们要链接的数据组织成了链表struct list_head可以位于结构中的任何位置可以给
struct list_head起任何名字在一个结构中可以有多个
list
内核链表之声明和初始化
内核代码中定义两个宏:
1 |
|
内核链表的插入
内核中两个插入函数:
1 | static inline void list_add(); //在链表头插入 |
- 实现了栈功能
1 | static inline void list_add_tail(); //尾部插入 |
- 实现了队列功能
内核的实现—抽象
1 | static inline void __list_add(struct list_head *new, struct list_head *prev, |
头部插入:将new插入到head和head->next之间,实现了在头部插入节点的功能—堆栈
1 | static inline void list_add(struct list_head * new, struct list_head *head) { |
尾部插入:将new插入到head和head->prev和head之间,这就实现了在尾部插入新节点的功能—-队列
1 | static inline void list_add_tail(struct list_head * new, struct list_head *head) { |
内核链表之删除
1 | static inline void __list_del(struct list_head * prev, struct list_head * next) { |
1 | static inline void list_del(struct list_head * entry) { |
注意:使用list_del()时,会将所要删除的节点(pos)的next和prev指向一个固定的值,所以想要通过 pos = pos->next访问下一个链表节点是不可能的,就会导致页错误,因为LIST_POISON是宏定义的一个不可访问的地址。
内核链表之遍历
1 |
|
这里遍历的是结构体成员,如何通过结构体成员逆向得到结构的位置?从而访问节点中的每个元素 ?
list_entry() 的分析
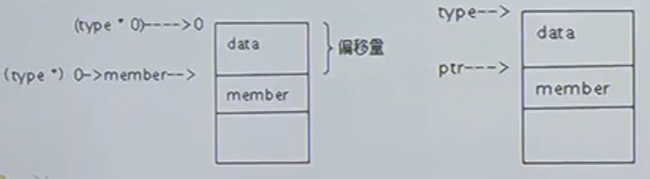
先找出list_head在结构体中的偏移量,如下图,然后ptr再减去这个偏移量就得到了结构体的起始地址。
list_entry() 宏
1 |
|
其中ptr为list_head结构体指针,type为你所定义的结构体类型,member 是结构体中 list_head结构体成员变量的名字。type的作用是为了强制转换,即宏中两次用到(type *), 指针ptr指向结构体type中的成员member; 通过指针ptr, 返回结构体type的起始地址。
(unsigned long)(&((type*)0)->member)是偏移量。
如何使用list_entry()
1 | struct mylist { |
list_entry() 的应用
进程结构体在内核中定义如下:
1 | struct task_struct { |
1 | struct task_struct *task, *p; |
链表API之应用
- list_init();
- listi_add();
- list_addtail();
- list_for_each();
- list_del();
- list_entry();
- …….
链表删除的不安全性
1 | list_for_each_safe(pos, q, &mylist.list) { |
两个宏之间的区别
1 |
|
1 |
|
内核代码的编写
内核模块
内核模块是linux内核向外部提供的一个插口,是内核的一部分但是并没有编译到内核中,其全称为动态可加载内核模块,简称模块
模块是一个独立的程序,它可以被单独编译,但不能独立运行。它在运行时被链接到内核作为内核的一部分在内核空间运行,这与运行在用户空间的进程是不同的。模块通常由一组函数和数据结构组成,用来实现一种文件系统、一个驱动程序或者其他内核上层的东西。
编写简单的内核模块
模块和内核都是在内核空间内运行,模块编程在一定意义上说就是内核编程。一个内核模块应该至少有两个函数,一个是module_init(), 是模块加载函数,当模块被插入到内核时调用它; 第二个是module_exit(), 是模块卸载函数,当模块从内核中移走时调用它。
1 |
|
进程源码分析
进程控制块
在Linux中把对进程的描述结构叫做task_struct
1 | struct task_struct { |
PCB是进程存在和运行的唯一标识
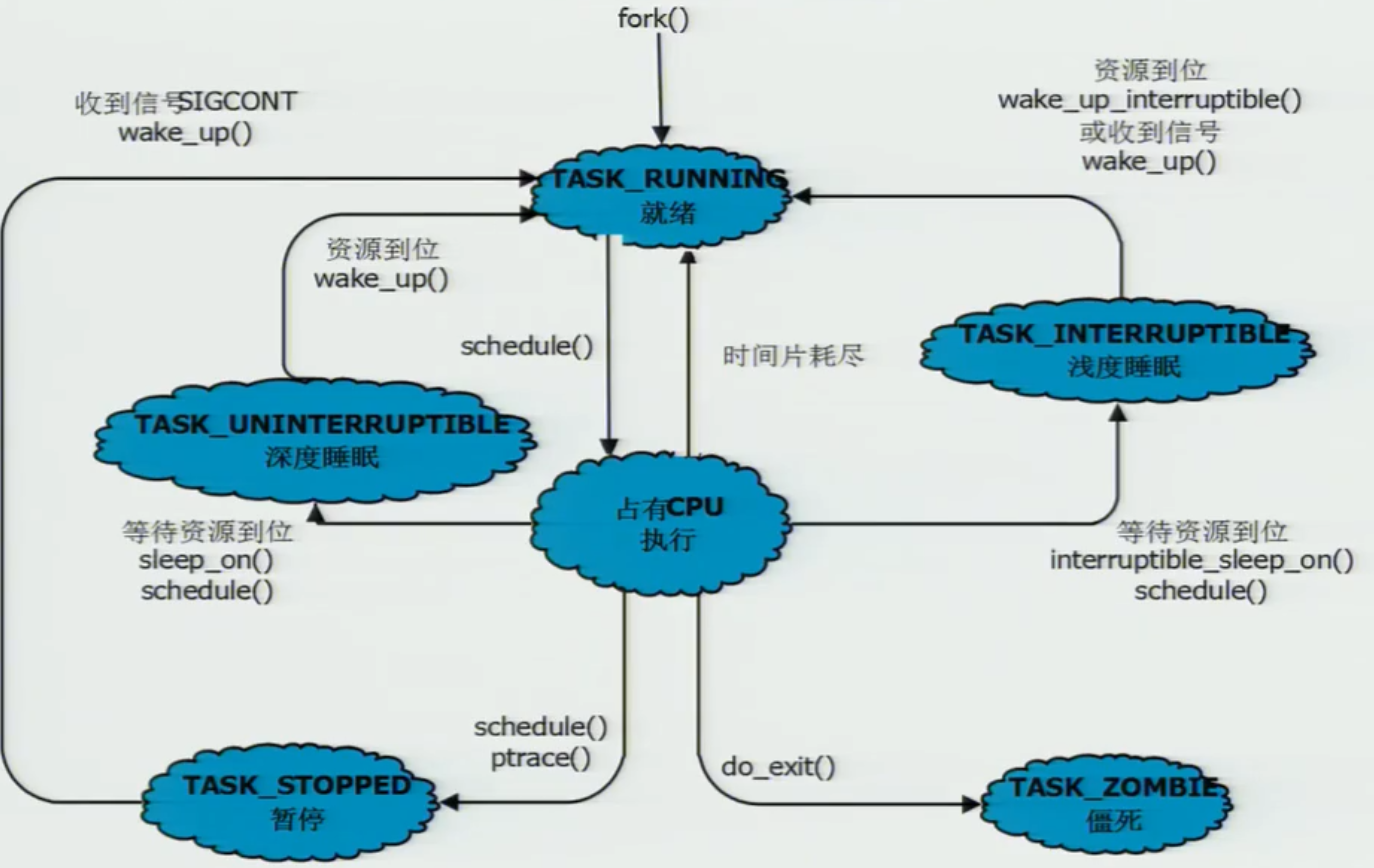
Linux进程状态及转换
进程控制块-进程标识符
每个进程都有一个唯一的标识符,内核通过这个标识符来识别不同的进程。
- 进程标识符PID 也是内核提供给用户程序的接口,用户程序通过PID对进程发号施令
- PID是32位的无符号整数,它被顺序编号
每个进程都属于某个用户组
task_struct结构中定义有用户标识符UID(User Identifier) 和组标识符GID(Group Identifier)- 这两种标识符用于系统的安全控制
